JDK1.8下的ConcurrentHashMap源码解析
上一篇博客介绍了HashMap的源码构成,现在我们趁热打铁继续看看ConcurrentHashMap吧。
简介
ConcurrentHashMap与HashMap的区别,就是ConcurrentHashMap是线程安全的。简单提一下HashTable,虽然HashTable也是线程安全的,HashTbale实现线程安全是通过用关键字synchronized修饰每个方法来实现的,当线程访问的方法正在被其他线程访问时,此线程必须进入阻塞或轮询状态,这就必然导致效率低下。 如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。下面就来介绍ConcurrentHashMap的优势之处。
ConcurrentHashMap在JAVA7中的实现原理
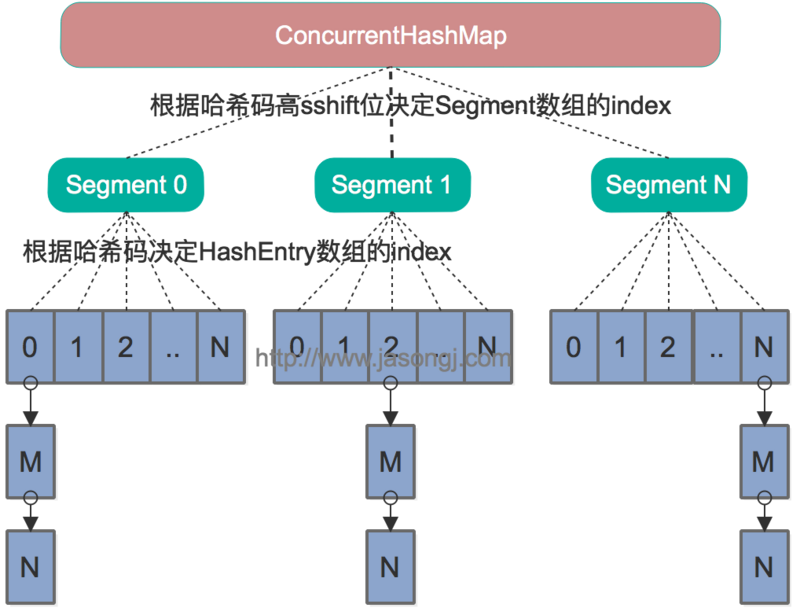
java8之前,ConcurrentHashMap是将数据分成一段一段存储的,给每一段数据配一把锁,当一个线程获得锁互斥访问一段数据时,其他段的数据也可以被其他线程访问。ConcurrentHashMap结构:每一个segment(分段锁)都是一个HashEntry<K,V>[] table, table中的每一个元素本质上都是一个HashEntry的单向队列(单向链表实现)。
ConcurrentHashMap在JAVA8中的实现原理
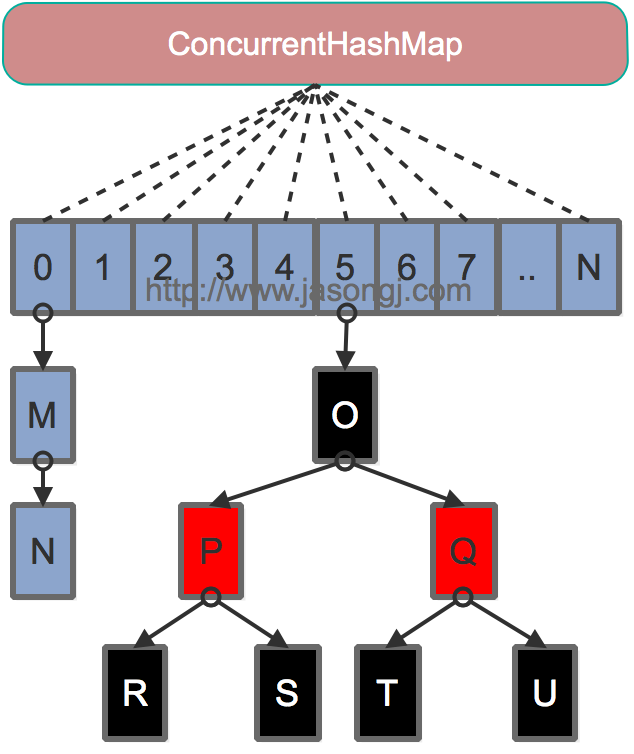
由图可见,Java8中实现已经抛弃了Segment分段锁机制,降低了锁的粒度,从对整个segment上锁到对Node上锁。利用CAS+Synchronized来保证并发更新的安全,底层依然采用数组+链表+红黑树的存储结构。
变量属性
1 | // 最大容量 |
1 | // 键值对桶数组 |
这里重点提一下sizeCtl变量,sizeCtl表示键值对总数阈值,通过CAS更新, 对所有线程可见
当sizeCtl < 0时,表示多个线程在等待扩容;
当sizeCtl = 0时,默认值;
当sizeCtl > 0时,表示扩容的阈值;
重要方法解析
Node() —— 键值对
1 | static class Node<K,V> implements Map.Entry<K,V> { |
这个Node内部类和HashMap的Node内部类很相似,但还是有以下区别
1:此Node类中对value和next属性设置了volatile同步锁
2:此Node类中不允许setValue方法直接改变Node的value域
3:此Node类中增加了find方法辅助map.get()方法
volatile关键字
这里介绍一下volatile关键词。volatile关键词可确保应用中的可视性,如果你将一个域声明为volatile的,那么只要对这个域产生了写操作,那么所有的读操作就能看见这个修改。即便使用了本地缓存,情况也是如此,volatile域会立即被写入到主存中,而读取操作就发生到主存中。
理解原子性和易变形是不同的概念这一点很重要。而非volatile域上的原子操作不必刷新到主存中去,因此其他读取该域的任务也不必看到这个新值。如果多个任务在同时访问某个域,那么这个域就应该时volatile的,否则,这个域就应该只能经由同步来访问。同步也会导致向主存中刷新,因此如果一个域完全由synchronized方法或语句块来防护,那就不必将其设置为是volatile的。TreeNode() —— Node for use in TreeBins
1 | // HashMap的TreeNode继承至LinkedHashMap.Entry;而这里继承至自己实现的Node,将带有next指针,便于treebin访问。 |
与HashMap相比,这里的TreeNode相当简洁;ConcurrentHashMap链表转树时,并不会直接转,正如注释(Nodes for use in TreeBins)所说,只是把这些节点包装成TreeNode放到TreeBin中,再由TreeBin来转化红黑树。TreeBin() —— 封装TreeNode
1 | // TreeBin用于封装维护TreeNode,包含putTreeVal、lookRoot、UNlookRoot、remove、balanceInsetion、balanceDeletion等方法,这里只分析其构造函数。 |
putVal()
1 | final V putVal(K key, V value, boolean onlyIfAbsent) { |
putVal()方法中,最重要地方就是synchronized(f){}操作通过对桶的首元素 = 链表表头 Or 红黑树根节点加锁,从而实现对整个桶进行加锁,有锁分离思想的体现。
table中的三个原子操作
1 | static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {// 获取索引i处Node |
addCount() —— CAS更新baseCount
1 | private final void addCount(long x, int check) { |
get()
1 | public V get(Object key) { |
get函数根据的hash值来计算在哪个桶中,再遍历桶,查找元素,若找到则返回该结点,否则,返回null。