dubbo系列之网络通信编码解码-consumer请求编码
简要
什么是编码、解码?
编码(Encode)称为序列化(serialization),它将对象序列化为字节数组,用于网络传输、数据持久化或者其它用途。
解码(Decode)反序列化(deserialization)把从网络、磁盘等读取的字节数组还原成原始对象(通常是原始对象的拷贝),以方便后续的业务逻辑操作。
看一张dubbo的通讯协议图
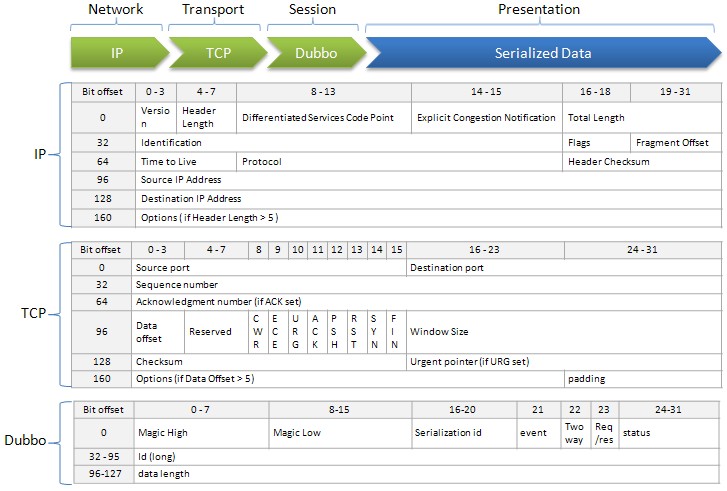
和其他网络通讯一样,都有IP和TCP,dubbo自己加了Dubbo协议,用于编解码。
为什么dubbo要用自己的编解码呢?因为tcp会出现粘包和拆包的问题,只有在出现粘包和拆包的情况下,才会调用dubbo自己的协议来处理这种情况。
先来一张图,了解一下什么是粘包和拆包
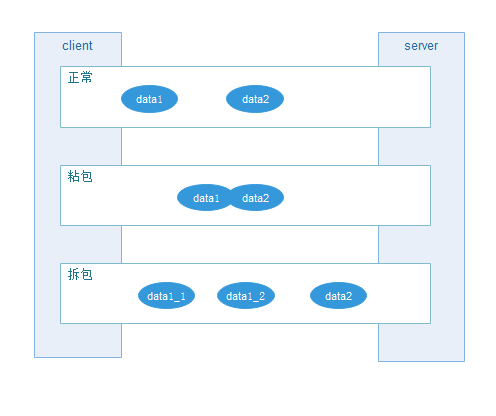
以往业界时如何解决粘包和拆包的?
1.消息的定长,例如定1000个字节
2.就是在包尾增加回车或空格等特殊字符作为切割。典型的FTP协议
3.将消息分为消息头消息体,消息头中包含表示消息总长度(或者消息体长度)的字段,通常涉及思路为消息头的第一个字段使用int32来表示消息的总长度。例如 dubbo
本篇博客就是介绍——将消息分为消息头消息体。
源码解析
NettyCodecAdapter类
encode()
1 | protected Object encode(ChannelHandlerContext ctx, Channel ch, Object msg) throws Exception { |
ExchangeCodec类
encode()
1 | public void encode(Channel channel, ChannelBuffer buffer, Object msg) throws IOException { |
encodeRequest()
1 | protected void encodeRequest(Channel channel, ChannelBuffer buffer, Request req) throws IOException { |
这样consumer的请求编码时候的encode就讲完了
总结一下
dubbo的消息头是一个定长的 16个字节。
第1-2个字节:是一个魔数数字:就是一个固定的数字
第3个字节:是双向(有去有回) 或单向(有去无回)的标记
第四个字节:空 (request 没有第四个字节)
第5-12个字节:请求id:long型8个字节。异步变同步的全局唯一ID,用来做consumer和provider的来回通信标记。
第13-16个字节:消息体的长度,也就是消息头+请求数据的长度。