前言
其实在前面几篇网络编程的文章里面,关于粘包和拆包已经讲的差不多了,由于本人这周五准备组内分享——dubbo的粘包和拆包,这篇博客就把dubbo处理粘包和拆包的流程梳理总结一下。
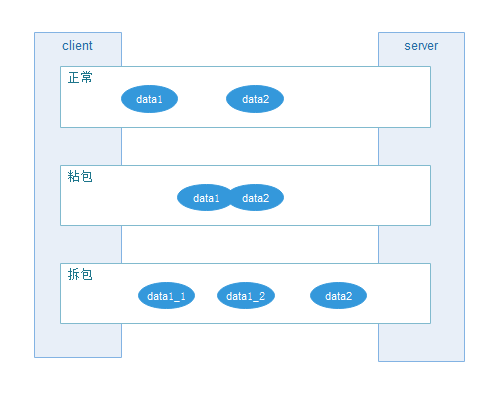
什么是粘包和拆包
TCP粘包拆包发生的原因
1.应用程序write写入的字节大小大于套接口发送缓冲区大小
2.进行MSS大小的TCP分段
3.以太网帧的payload(有效数据)大于MTU进行IP分片
以往业界时如何解决粘包和拆包的?
1.消息的定长,例如定1000个字节
2.就是在包尾增加回车或空格等特殊字符作为切割。典型的FTP协议
3.将消息分为消息头消息体,消息头中包含表示消息总长度(或者消息体长度)的字段,通常涉及思路为消息头的第一个字段使用int32来表示消息的总长度。例如 dubbo
dubbo为什么没有选择netty原生的粘包和拆包的方法,选择自定义?
因为dubbo的协议栈是自定义的,里面包含消息头和消息体两个部分,消息头中包含消息类型、协议版本、协议魔数以及playload长度等信息。而netty只能处理一些通用简单的协议栈,并不能处理高度自定义的协议栈,所以dubbo自定义了属于自己的一套粘包和拆包的解决办法。
消息头和消息体长什么样?
以provider给consumer发送的数据包为例
ExchangeCodec类—encodeResponse()
1 | Serialization serialization = getSerialization(channel); |
dubbo的消息头是一个定长的 16个字节。
第1-2个字节:是一个魔数数字:就是一个固定的数字
第3个字节:序列号组件类型,它用于和客户端约定的序列号编码号
第四个字节:它是response的结果响应码 例如 OK=20
第5-12个字节:请求id:long型8个字节。异步变同步的全局唯一ID,用来做consumer和provider的来回通信标记。
第13-16个字节:消息体的长度,也就是消息头+请求数据的长度。
这样,接着看consumer接受到编码后的消息体,是如何处理的
NettyCodecAdapter.InternalDecoder类
messageReceived()
分两个部分
1 | //首先判断当前decoder对象的buffer中是否有可以读取的消息,若有,则合并。并将对象赋值给message局部变量 |
1 | try { |
DubboCountCodec类
decode()
1 | public Object decode(Channel channel, ChannelBuffer buffer) throws IOException { |
这里暂存了当前buffer的读索引,同样也是为了后面的回滚。可以看到当decode返回的是NEED_MORE_INPUT则表示当前的buffer中数据不足,不能完整解析出一个dubbo协议栈,同时将buffer的读索引回滚到之前暂存的索引并且退出循环,将结果返回。
ExchangeCodec类
decode()
1 | protected Object decode(Channel channel, ChannelBuffer buffer, int readable, byte[] header) throws IOException { |
##总结
dubbo在处理tcp的粘包和拆包时是借助InternalDecoder的buffer缓存对象来缓存不完整的dubbo协议栈数据,等待下次inbound事件,合并进去。所以说在dubbo中解决TCP拆包和粘包的时候是通过buffer变量来解决的
上面的方法就解决了粘包了拆包的问题了
若出现粘包,就会根据它的请求长度进行截取;
若出现拆包,数据会不完整,就进入循环重新读取,直到取到完整数据。
END