线程安全之原子操作
案例
1 | package com.wyj.jvm.lock; |
执行结果
1 | 13015 |
结果并没有达到理想的20000,下次运行结果还是会变,这就是多线程下的不可预测性
为什么会出现运行结果< = 20000呢?
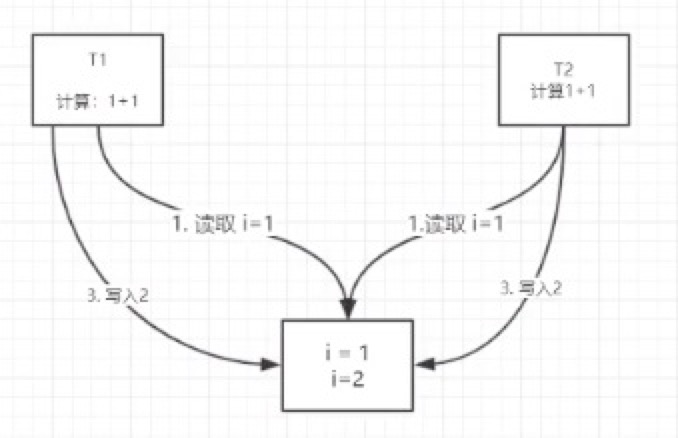
读取是不分先后顺序的,在写入的时候有两个或多个线程同时写入i=2,但是循环已经进行了三次或三次以上,这样就导致了行结果< = 20000。
volatile保证读取的时候读的i值相同,保证可见性,但是不能解决原子操作的问题。
为什么一个i++操作会出现线程不安全呢
反编译一下class文件: javap -v LockDemo.class
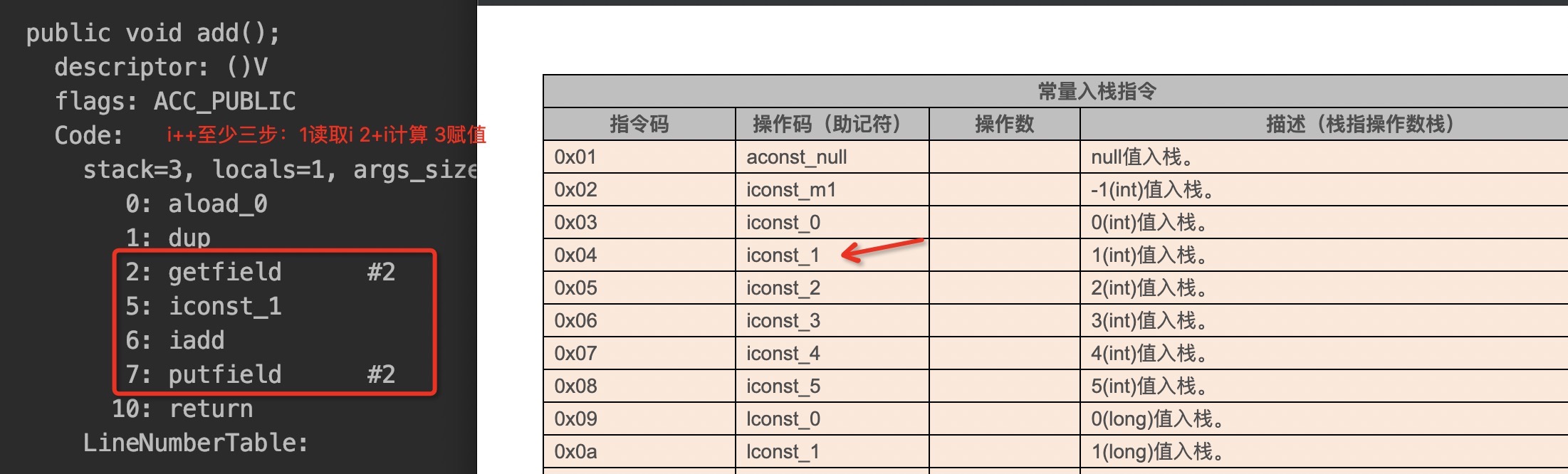
从字节码角度i++这个操作,有三步。
竞态条件与临界区
1 | public class Demo { |
多个线程访问了相同的资源,向这些资源做了写操作时,对执行顺序有要求。
临界区:incr方法内部就是临界区域,关键部分代码的多线程并发执行,会对执行结果产生影响。
竞态条件:可能发生在临界区域内的特殊条件。多线程执行incr方法中的i++关键代码时,产生竞态条件。
共享资源
如果一个代码是线程安全的,则他不包含竞态条件。只有当多个线程更新共享资源时,才会发生竞态条件。
栈封闭时,不会在线程之间共享的变量,都是线程安全的。
局部对象引用本身不共享,但是引用的对象存储在共享堆中。如果方法内创建的对象,只是在方法中传递,并且不对其他线程可用,那么也是线程安全的。
原子操作
原子操作可以是一个步骤,也可以是多个操作步骤,但是其顺序不可以被打乱,也不可以被切割而只执行其中的一部分(不可中断性)。
将整个操作视作一个整体,资源在该次操作中保持一致,这就是原子性的核心特征。
存在竞态条件,线程不安全,需要转变为原子操作才能安全。方式:循环CAS、锁。
Atomic相关类和CAS机制
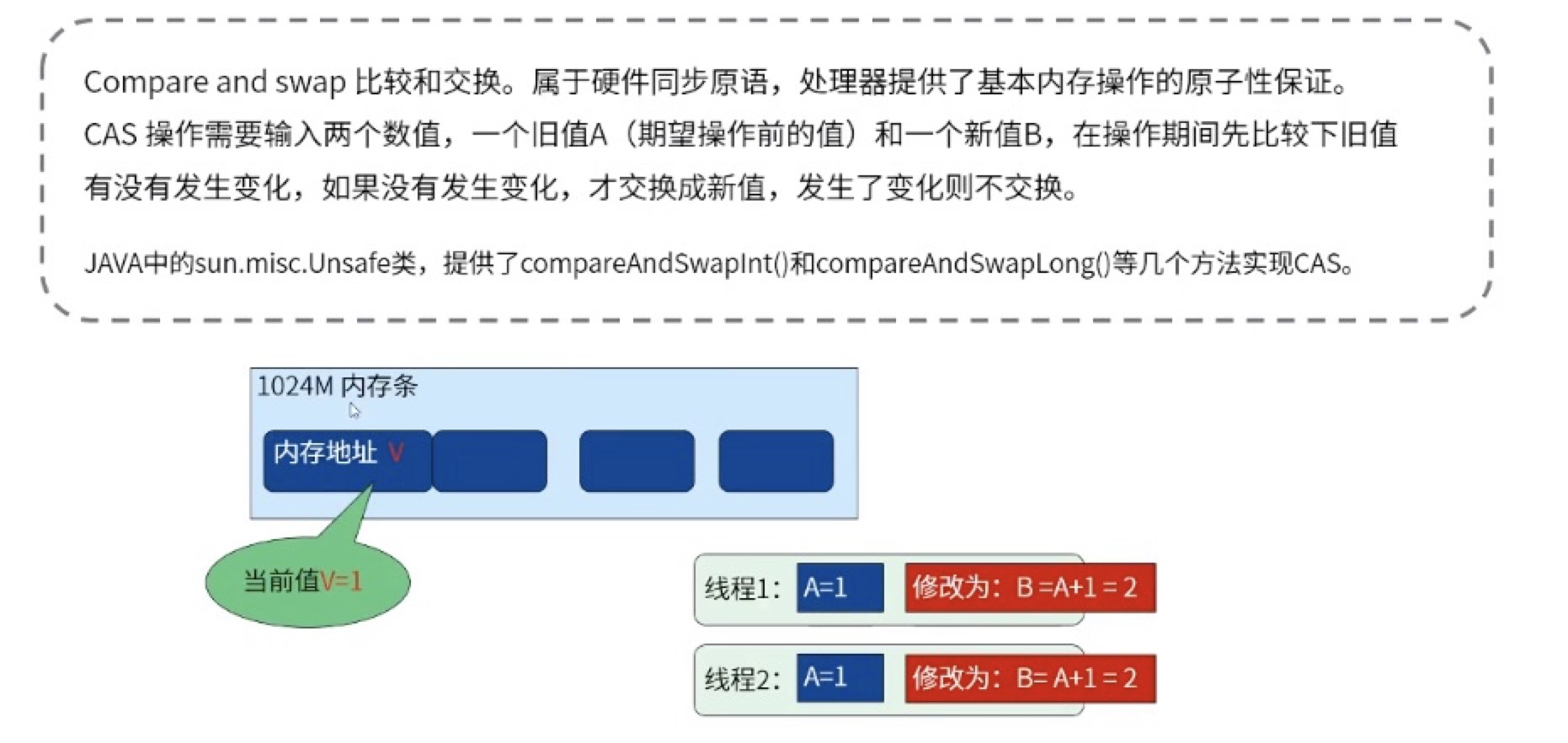
CAS机制
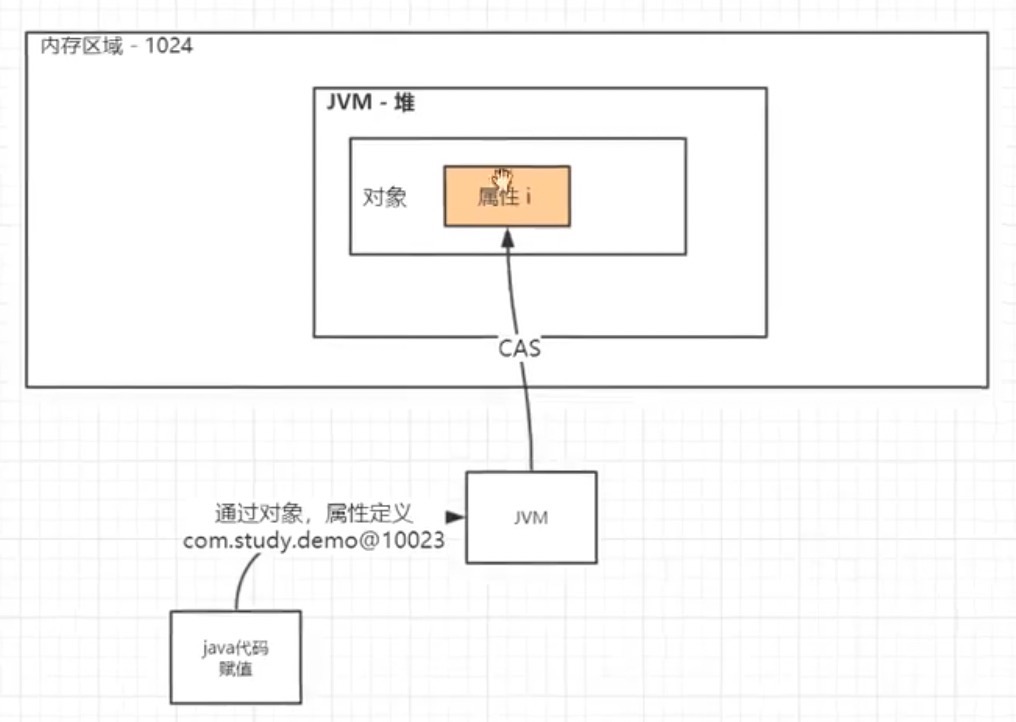
上面的demo经过CAS改造后
1 | package com.wyj.jvm.lock; |
输出结果
1 | 20000 |
这样输出结果一直是20000,保证了线程安全。
CAS的三个问题
1.循环➕CAS,自旋的实现让所有的线程都处于高频运行,争抢CPU执行时间的状态。如果操作长时间不成功,会带来很大的CPU资源消耗。
2.仅针对单个变量的操作,不能用于多个变量来实现原子操作。
3.ABA问题(无法体现出数据的变动)。
利用JDK的封装类Atomic类,上面CAS demo可以简化为
1 | public class LockAtomicDemo { |
看下incrementAndGet
1 | public final int incrementAndGet() { |
1 | public final int getAndAddInt(Object var1, long var2, int var4) { |
可见Atomic封装类里面实现的还是循环➕CAS的方法封装
J.U.C包内的原子操作封装类**
AtomicBoolean:原子更新布尔类型
AtomicInteger:原子更新整型
AtomicLong:原子更新长整型
AtomicIntegerArray:原子更新整型数组里的元素
AtomicLongArray:原子更新长整型数组里的元素
AtomicReferenceArray:原子更新引用类型数组里的元素
AtomicIntegerFieldUpdater:原子更新整型的字段的更新器
AtomicLongFieldUpdater:原子更新长整型的字段的更新器
AtomicReferenceFieldUpdater:原子更新引用类型里的字段
针对问题一:CAS是针对内存的运算,虽然内存运算是纳秒级别的,但是高并发下,性能还是有影响
所以1.8更新
更新器:DoubleAcccumulator、LongAccumulator
计数器:DoubleAdder、 LongAdder
计数器增强版,高并发下性能更好
频繁更新但不太频繁读取的汇总统计信息时使用,因为汇总的时候要获取每个操作单元的值。
分成多个操作单元,不同线程更新不同的单元
只有需要汇总的时候才计算所有单元的操作
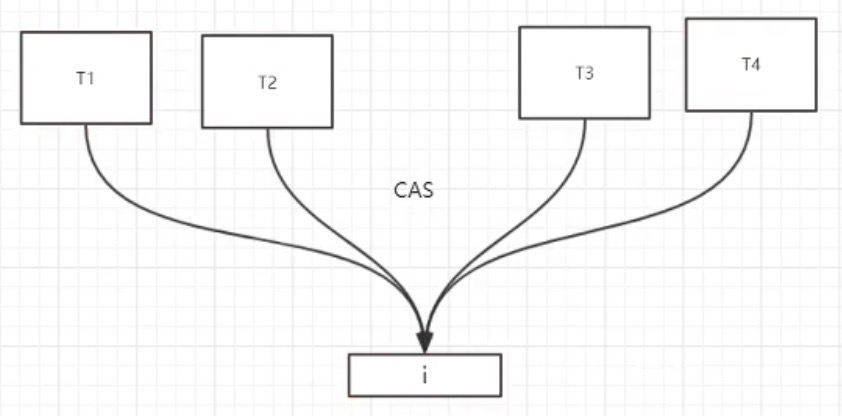
CAS 1.7
CAS 1.8
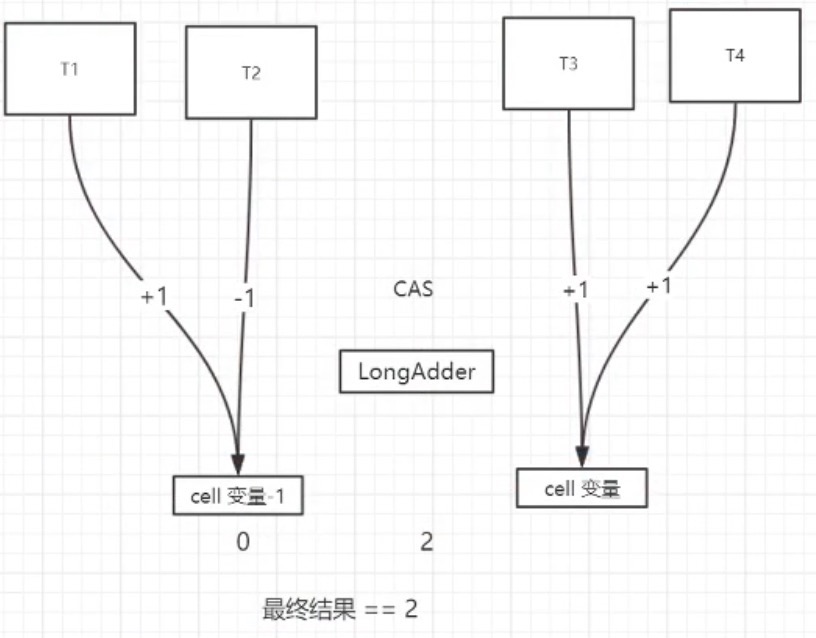
这就类似于大数据mapReduce,hashmap分段锁,是分而治之的思路,减少了CAS冲突。
看个demo下CAS
问题三:ABA问题
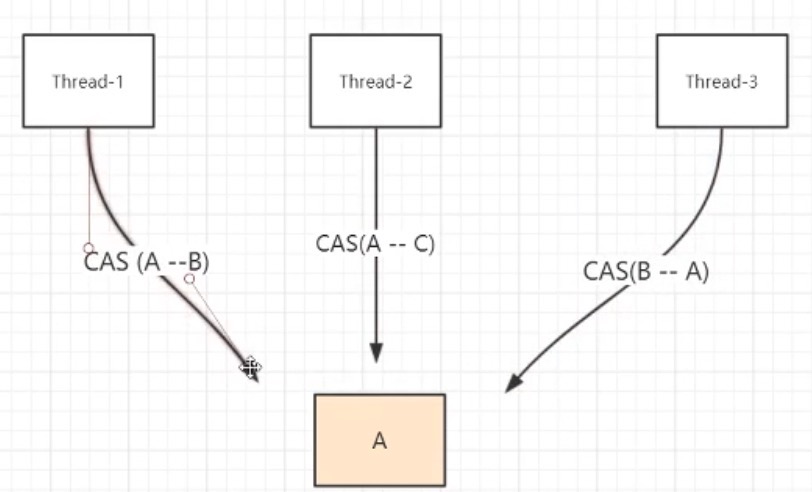
线程1将A修改为B, 线程2这个时候应该是修改失败的,但是线程3比线程2早一步执行,将B修改为A,线程2无法感知数据发生了变化,将A修改为C,修改成功了,这就是ABA问题。
所以java在AtomicStampedReference、AtomicMarkableReference等原子操作类解决了这个问题
看下AtomicStampedReference构造方法
1 | public AtomicStampedReference(V initialRef, int initialStamp) { |
再看下构造函数
1 | public AtomicReference(V initialValue) { |
新增了initialStamp类似版本号的东西(默认从0开始)
再看下AtomicStampedReference.compareAndSet方法
1 | public boolean compareAndSet(V expectedReference, |
这样再每次比较交换的时候都会比较版本号,解决了ABA的问题。