并发容器类list_set_queue
List
CopyOnWriteArrayList——容器即写时复制的容器
和ArrayList比较,优点是并发安全,缺点有两个:
1、多了内存占用:写数据是copy一份完整的数据,单独进行操作。占用双份内存。
2、数据一致性:数据写完之后,其他线程不一定是马上读取到最新内容。
add
1 | public boolean add(E e) { |
get
1 | private E get(Object[] a, int index) { |
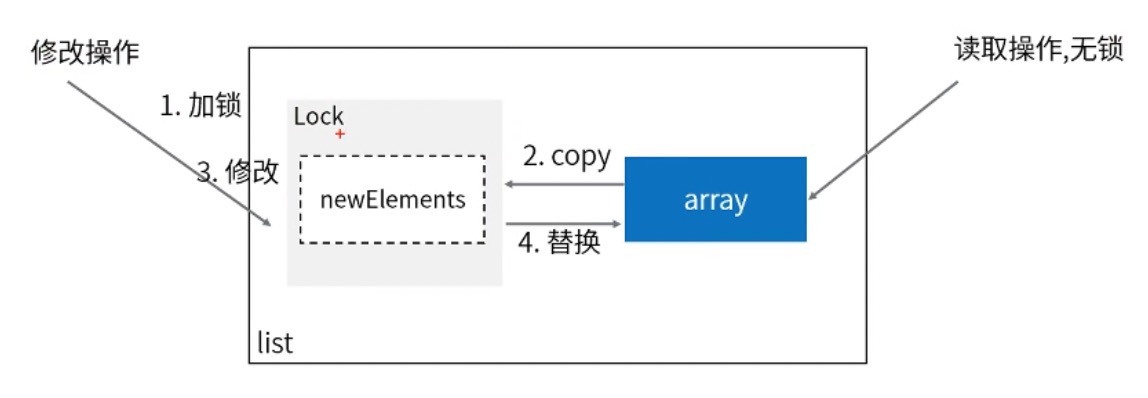
add方法一开始就加上了锁来实现线程安全
那么为什么要copy一份完整数据呢?这样就不会出现读到一半的数据,线程安全,但是会出现数据不一致。
set
💡set和list重要区别:不重复
| 实现 | 原理 | 特点 |
|---|---|---|
| HashSet | 基于HashMap实现 | 非线程安全 |
| CopyOnWriteArraySet | 基于CopyOnWriteArrayList | 线程安全 |
| ConcurrentSkipListSet | 基于ConcurrentSkipListMap | 线程安全,有序,查询快 |
猜想:set如何保证不重复,插入的时候比对一下,无重复再插入?
这样不可避免的会造成性能低
HashSet
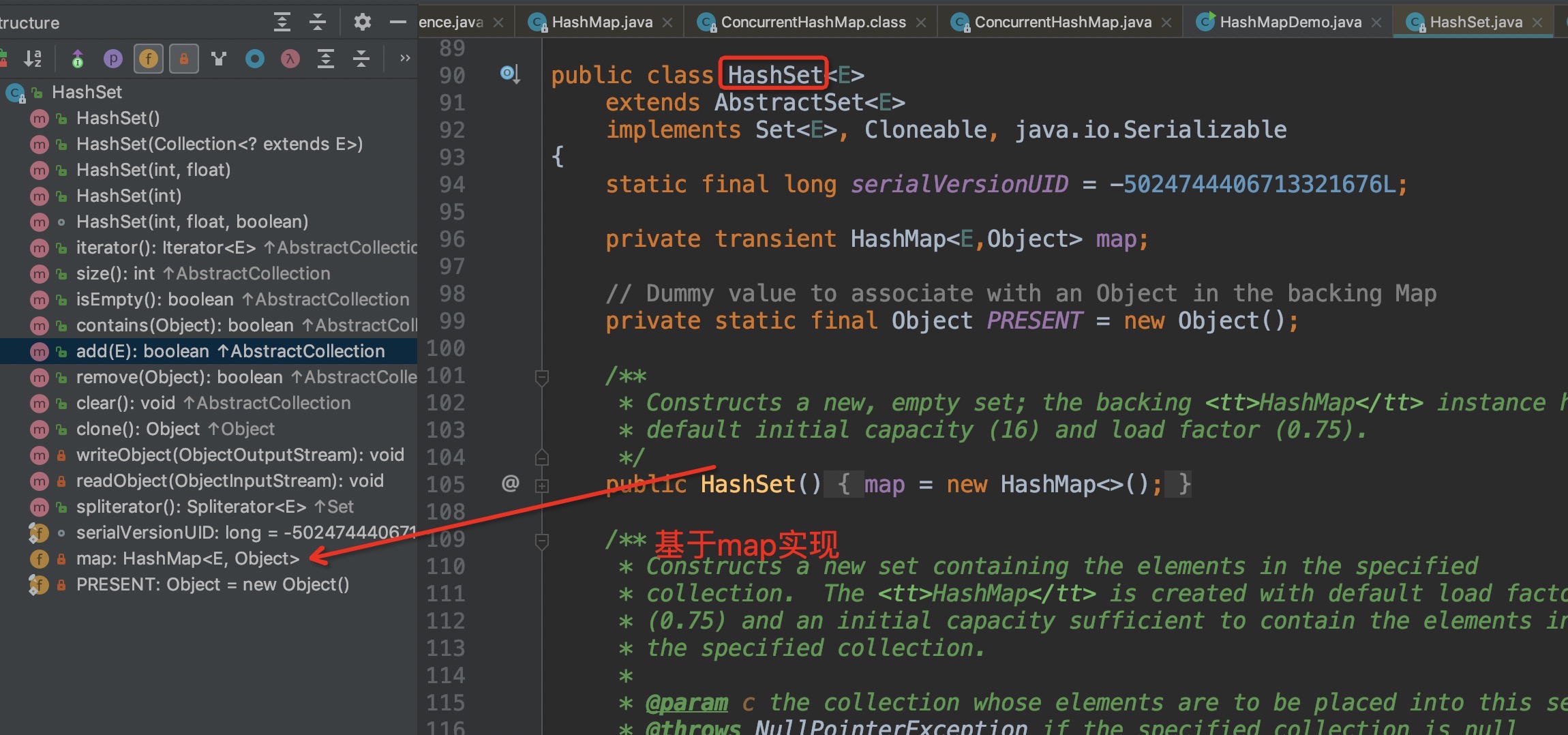
1 | public class HashSet<E> |
add
1 | public boolean add(E e) { |
可见,HashSet是将元素放在在map的key位置,而map的value位置是放的PRESENT这个虚拟值,而HashMap的key是不能重复的,所以HashSet就保证了元素不可重复。
CopyOnWriteArraySet
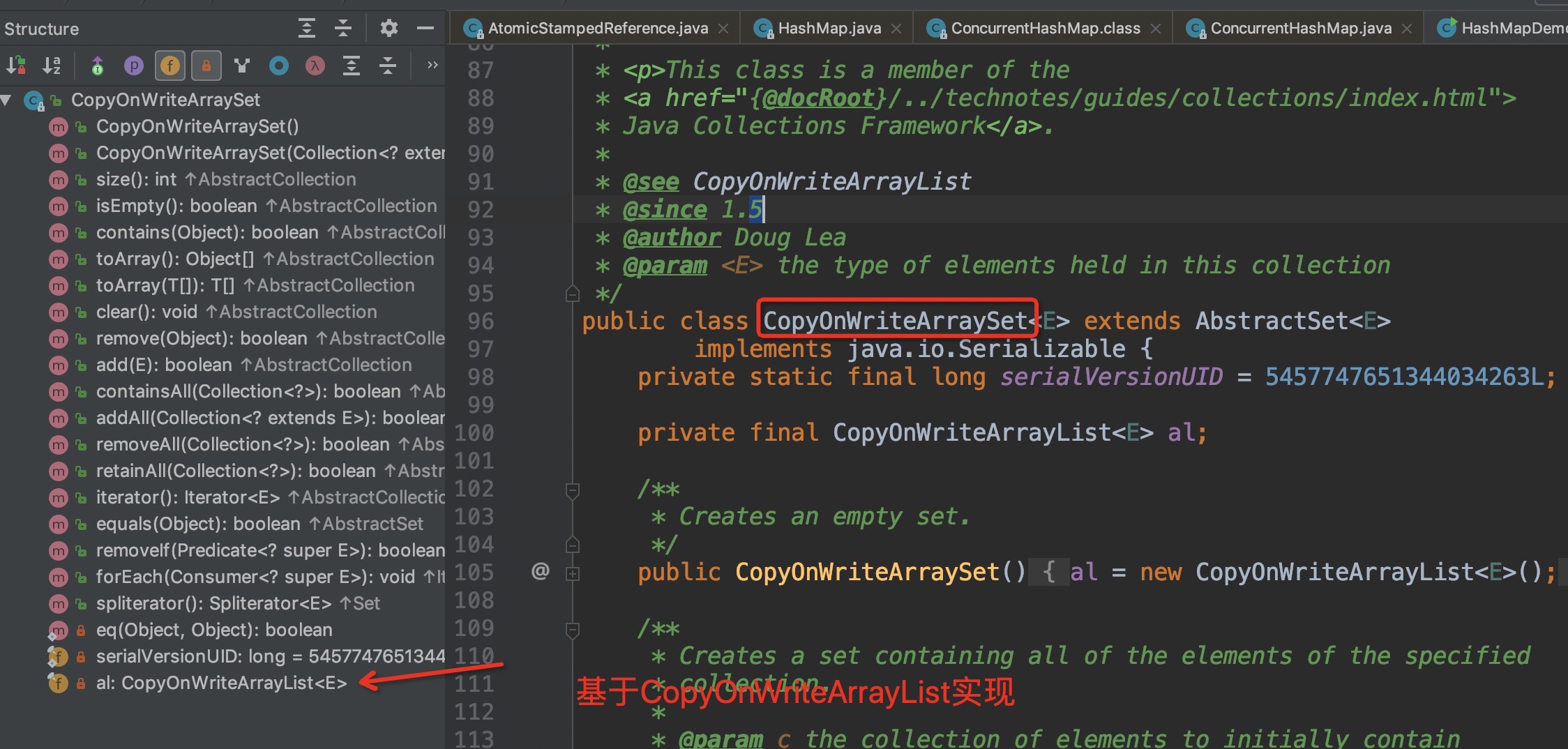
基于list如何实现不重复?
add
1 | /** |
1 | public boolean addIfAbsent(E e) { |
1 | /** |
ConcurrentSkipListSet
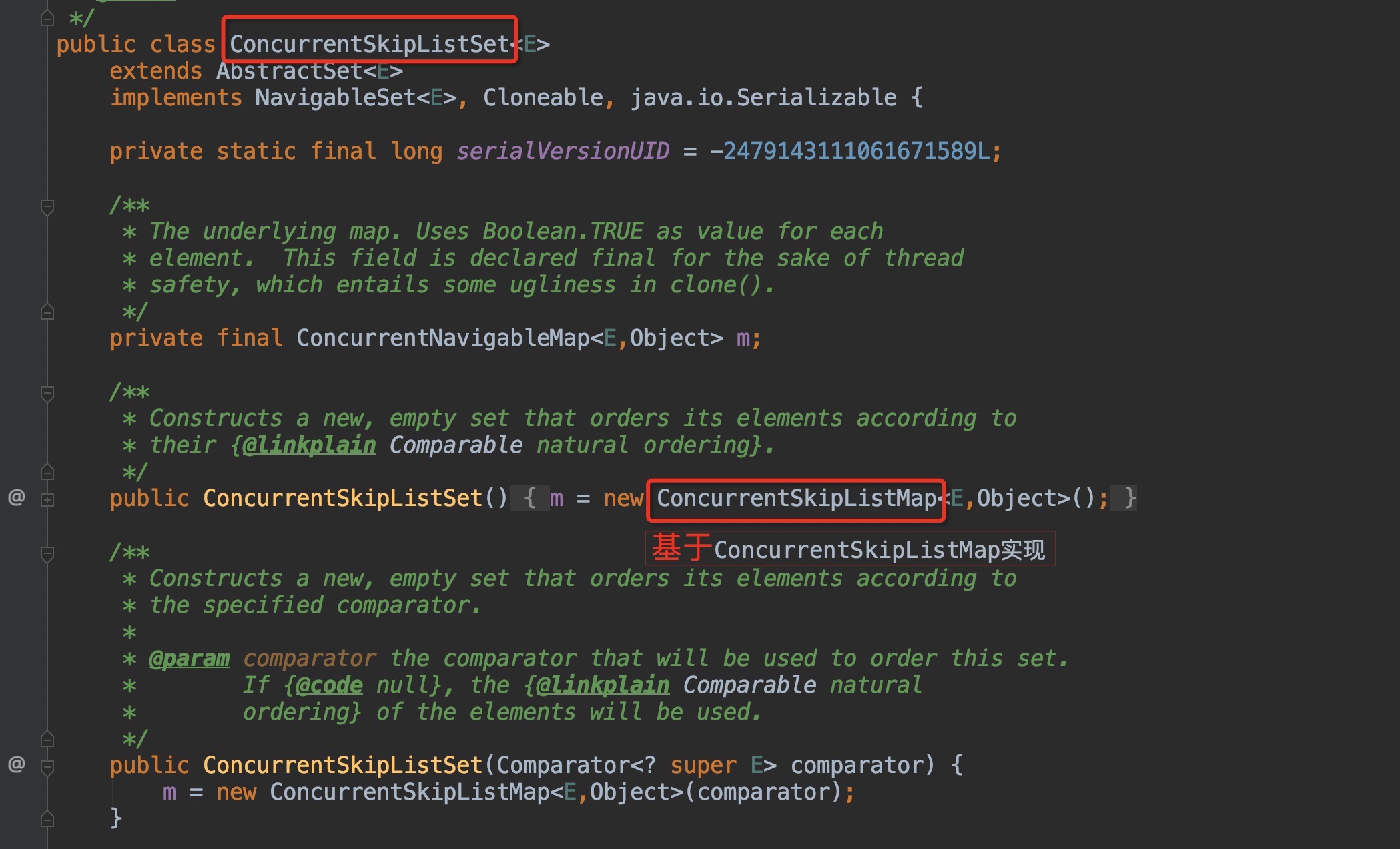
基于map的实现,相对于基于list的实现会更高效,因为list里面会不可避免的出现多次比较。
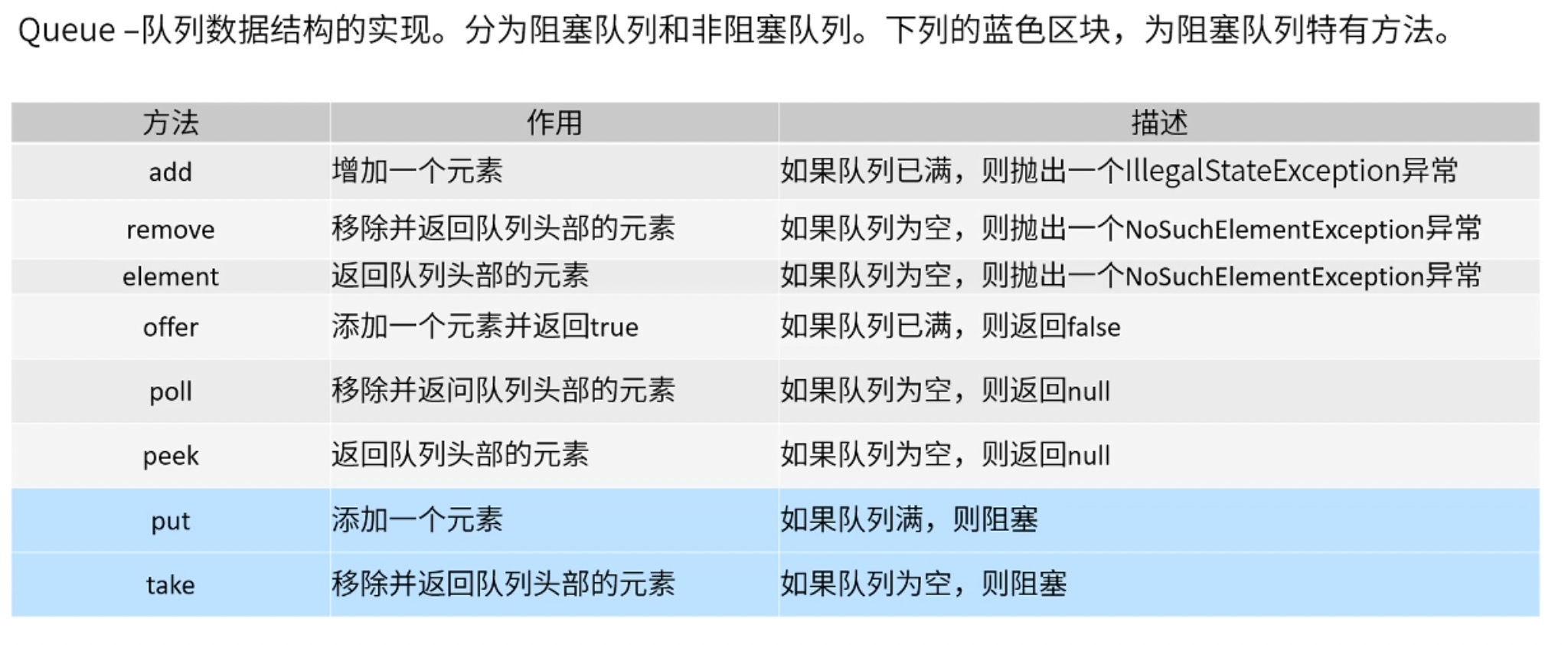
Queue
运用场景:线程池、数据库连接池、消息队列
在rocketmq中,消息会先利用queue存储到内存中,在写入硬盘(刷盘),这样就不会在机器重启的情况下丢失消息,实现持久化。
API
ConcurrentLinkedQueue
offer
1 | /** |
poll
1 | public E poll() { |
size
1 | /** |
在ConcurrentLinkedQueue中的size方法会轮询整个Queue
为什么不在offer的时候直接size++?
因为size++这个操作本身就是非线程安全的,而ConcurrentLinkedQueue是无锁编程(CAS),所以放在offer里面并不合适,这样会破坏ConcurrentLinkedQueue线程安全的立意。
💡由于ConcurrentLinkedQueue中的size方法会轮询整个Queue,若仅仅只是想判断是否为空建议使用isEmpty。
在数据库连接池中,获取连接的时候,如果连接不够用,这时候需要阻塞等待,这是ConcurrentLinkedQueue不具备的功能。
ArrayBlockingQueue——— 线程安全、阻塞
put——阻塞式入队列
1 | /** |
💡offer方法不会阻塞,若队列满了,则直接返回false
take—阻塞式获取队列头部
1 | public E take() throws InterruptedException { |
💡ReentrantLock.lockInterruptibly允许在等待时由其它线程调用等待线程的Thread.interrupt方法来中断等待线程的等待而直接返回,这时不用获取锁,而会抛出一个InterruptedException。 ReentrantLock.lock方法不允许Thread.interrupt中断,即使检测到Thread.isInterrupted,一样会继续尝试获取锁,失败则继续休眠。只是在最后获取锁成功后再把当前线程置为interrupted状态,然后再中断线程。
🗣🥑🥝💎💡
LinkedBlockingQueue
构造方法
1 | public LinkedBlockingQueue(int capacity) { |
put
1 | /** |
offer
1 | /** |
ArrayBlockingQueue和LinkedBlockingQueue 入队列和出队列对比,原理相同
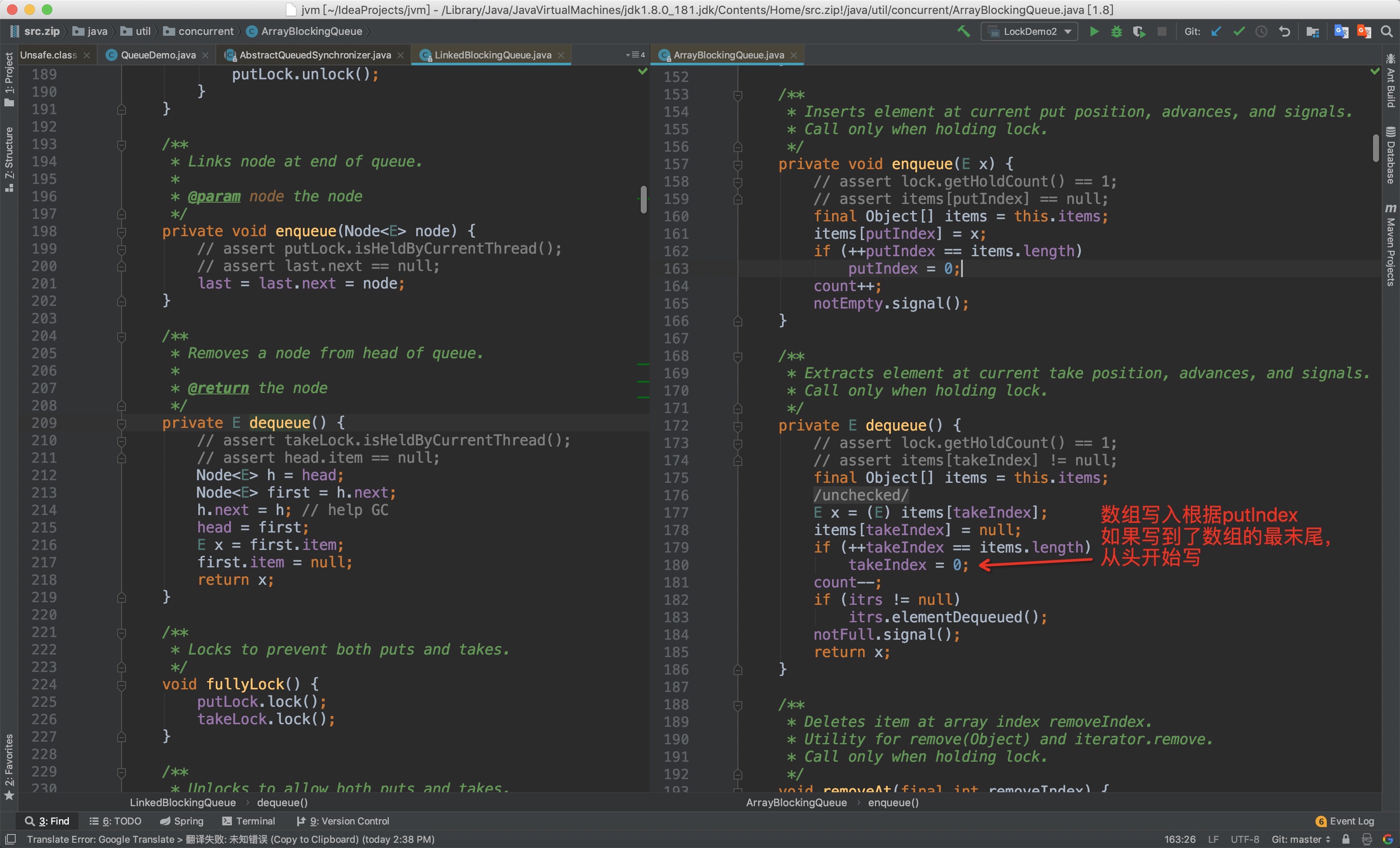
不同之处 参考https://zhidao.baidu.com/question/553304139806031732.html
案例:Tomcat实现的数据库连接池
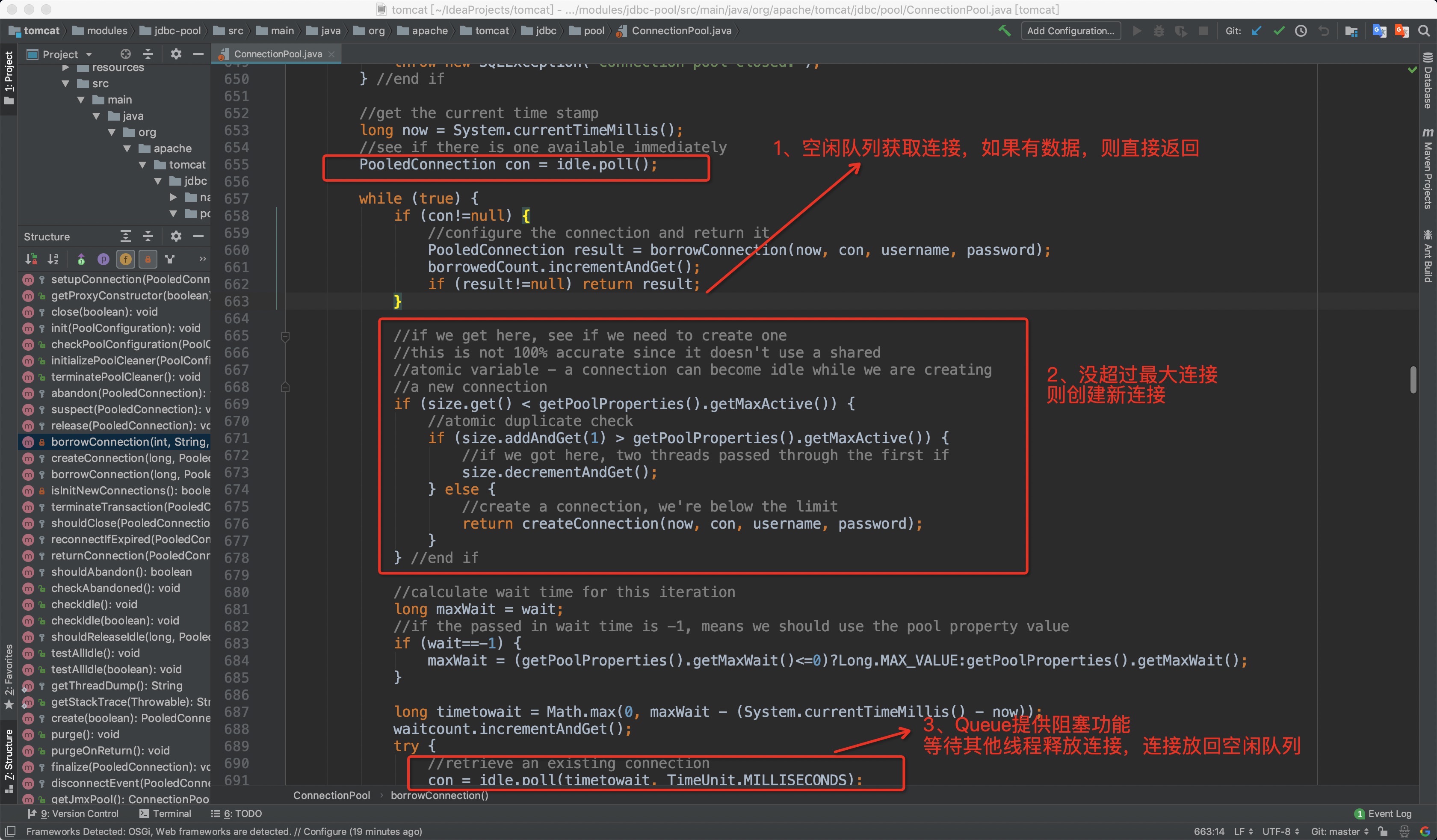
为什么tomcat选择用LinkedBlockingQueue实现的数据库连接池,而不是ArrayBlockingQueue?
因为ArrayBlockingQueue实现的队列中的锁是没有分离的,即生产和消费用的是同一个锁;
LinkedBlockingQueue实现的队列中的锁是分离的,即生产用的是putLock,消费是takeLock。数据库连接池的场景读取和写入应该是分离的,所以LinkedBlockingQueue更为适合。
PriorityBlockingQueue——— 优先级阻塞队列 线程安全
PriorityQueue是非线程安全的
利用堆排序实现排序
DelayQueue——— 延时队列
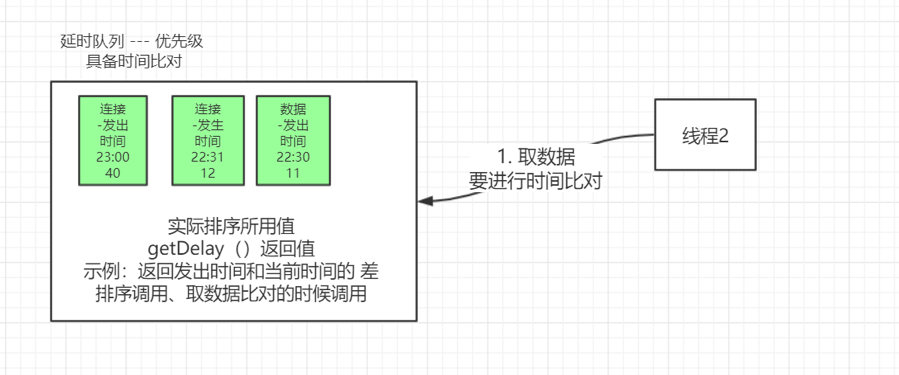
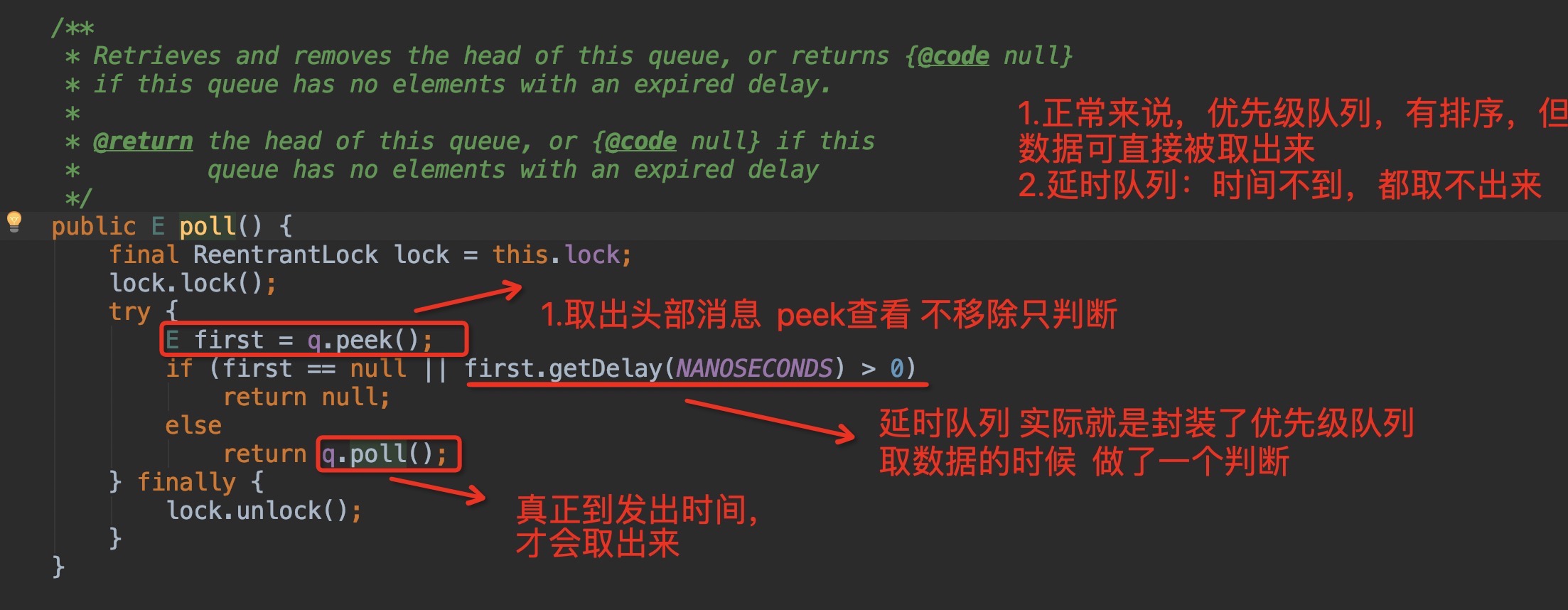
poll
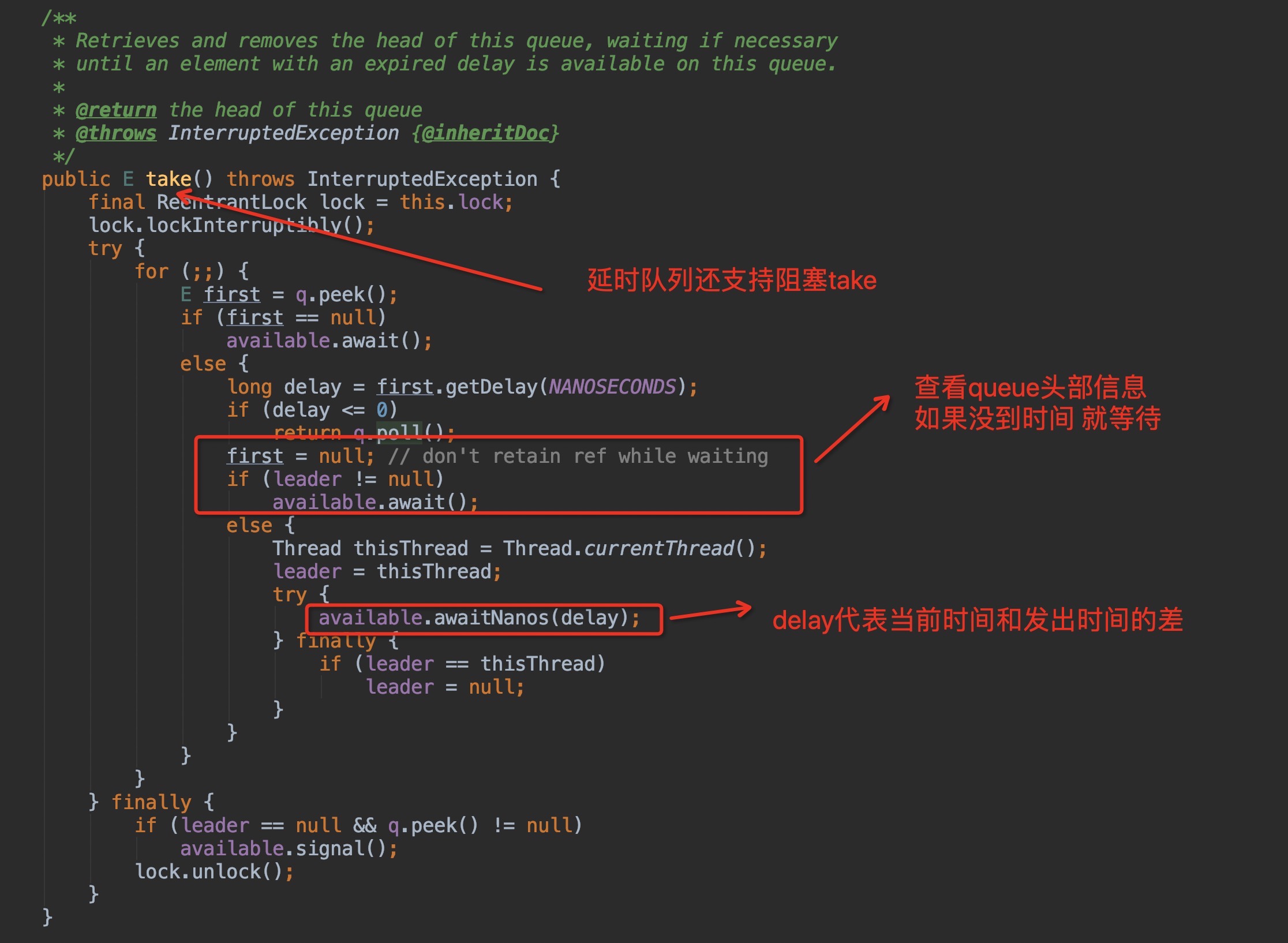
take—— 阻塞式获取,不需要轮询
延时队列典型场景就是计划任务,线程池 ——— ScheduledThreadPoolExecutor是一个使用线程池执行定时任务的类,ScheduledThreadPoolExecutor内部自己实现了一个类似延时队列的DelayWorkQueue