HashMap ConcurrentHashMap1.7和1.8
HashMap1.7
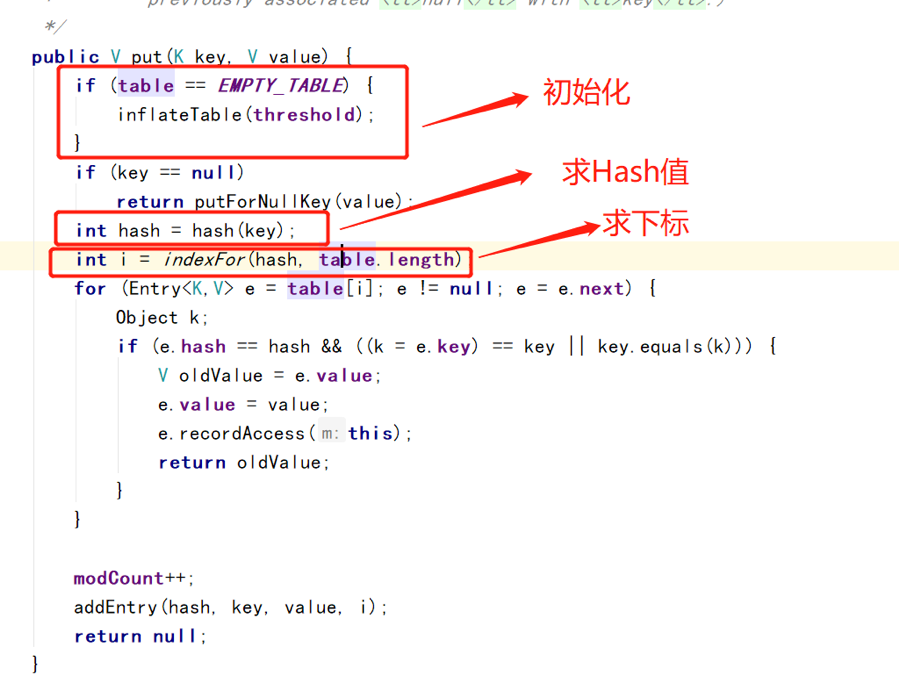
初始化


put

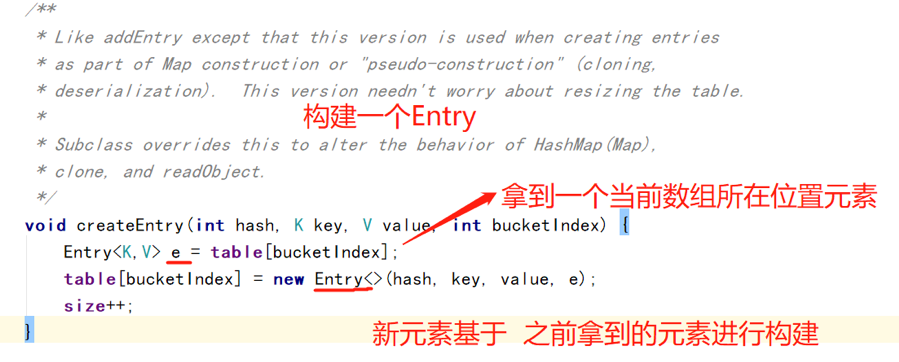
创建新的Entry
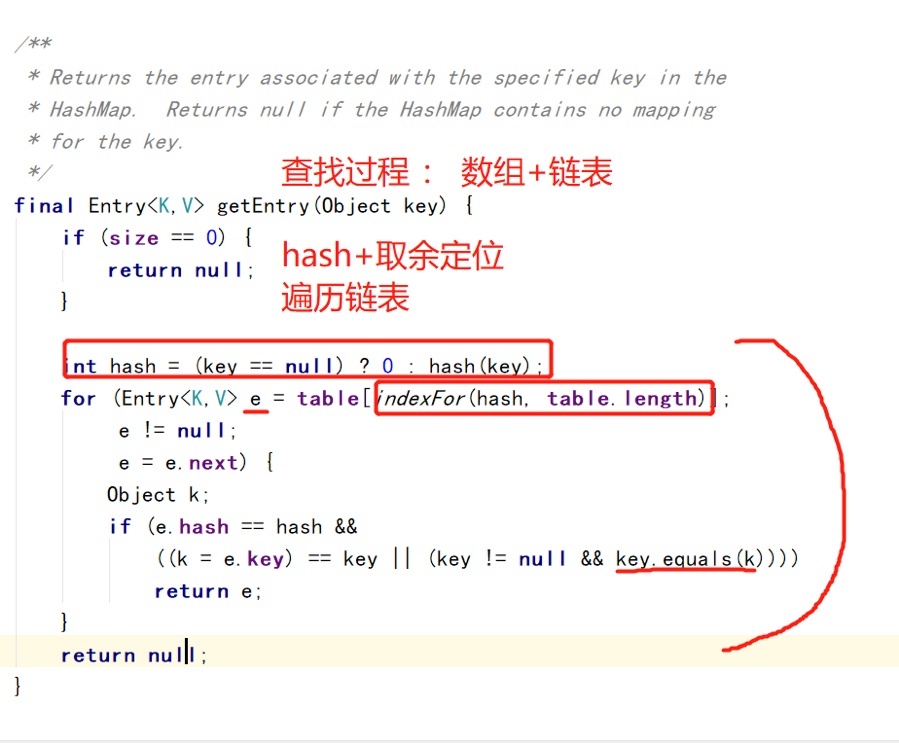
get
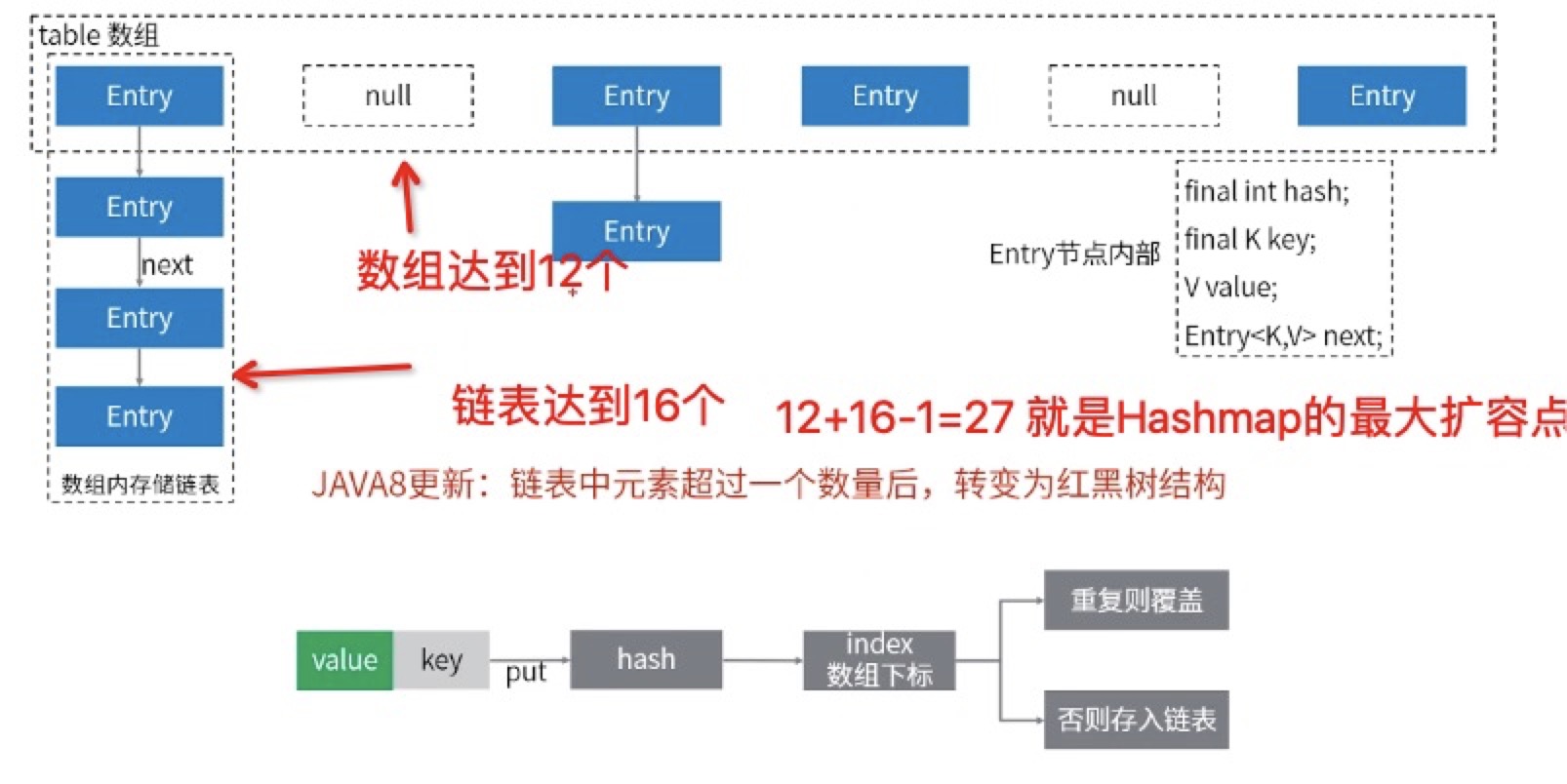
扩容机制
1 | void addEntry(int hash, K key, V value, int bucketIndex) { |
那么size为16的hashMap最多到底能塞多少个元素?
hashmap是数组+链表的结构
利用扩容条件,我们可以
1 | /** |
HashMap1.8(与1.7的不同之处)
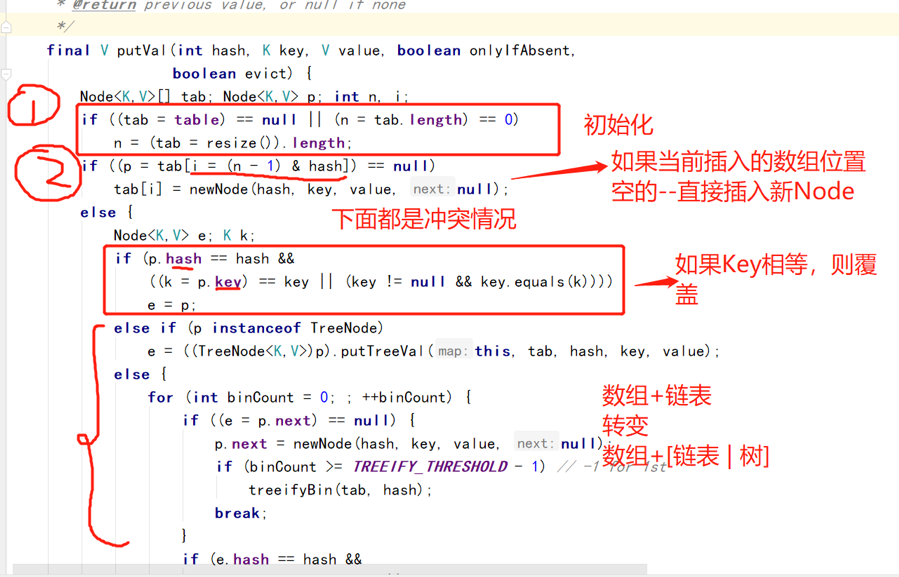
扩容

所以1.8的最大扩容临界点就是12
put
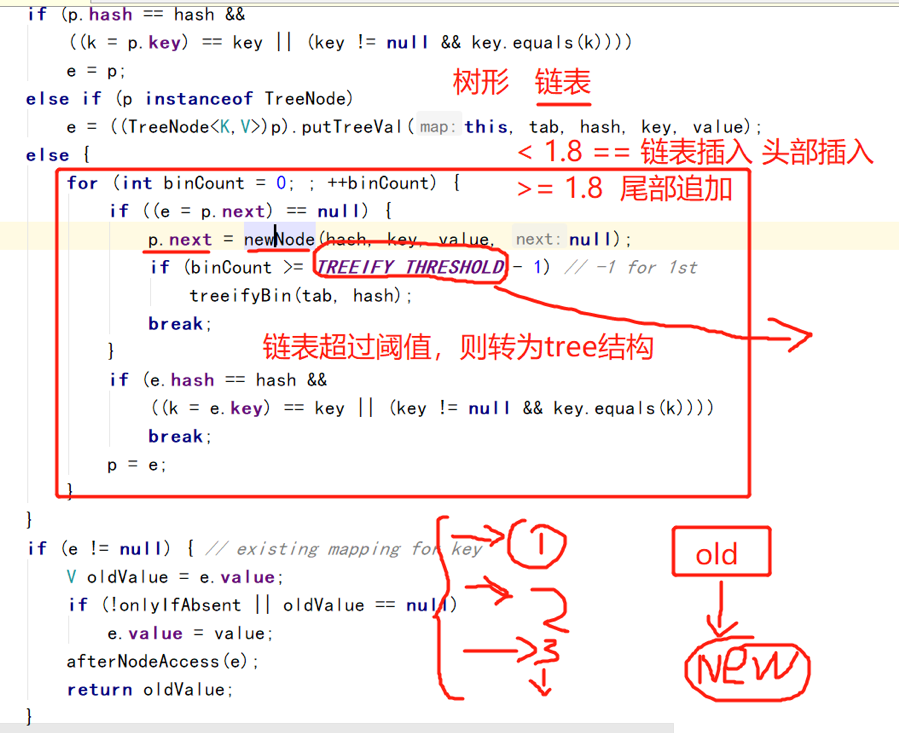
为什么要转换?
在1.7的hashMap中,若表size从512扩容至1024,链表的最大长度也增大到1024,这样若出现新插入的五百多个元素全部进入第一个链表,导致链表长度过大,则会造成查询速度很慢的情况。所以1.8有了树形结构。
树:构建树结构,复杂(插入复杂),所以复杂jdk1.8是在达到一定阈值(8)的时候,再转换成树
Java8扩容时机
1、 超过阈值(默认12)
2、 当链表长度超过8,且,数组长度<64的时候(代码如下图)
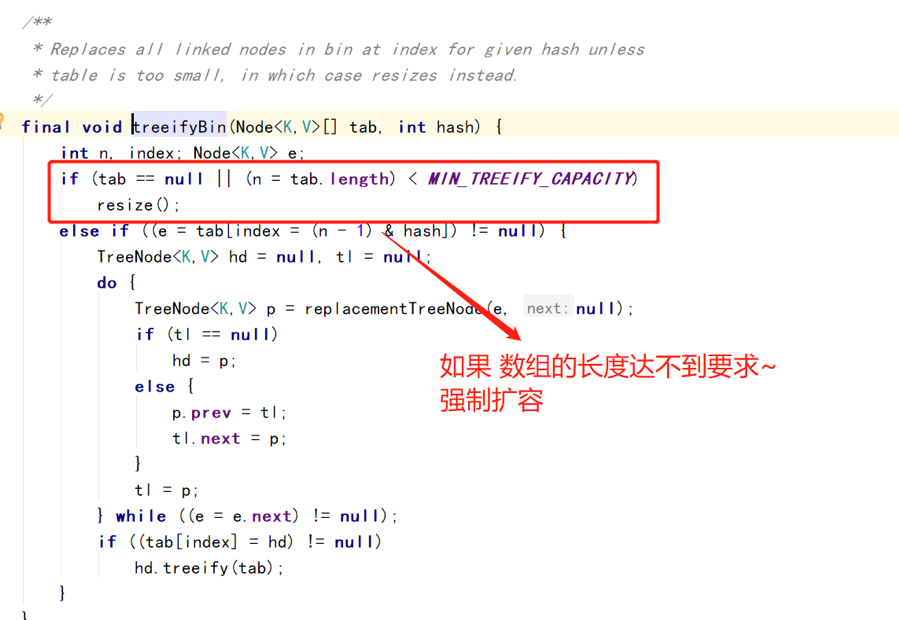
所以1.8的hashmap扩容时机最大是12,最小是9。
并发安全
jdk1.7 CurrentHashMap
初始化

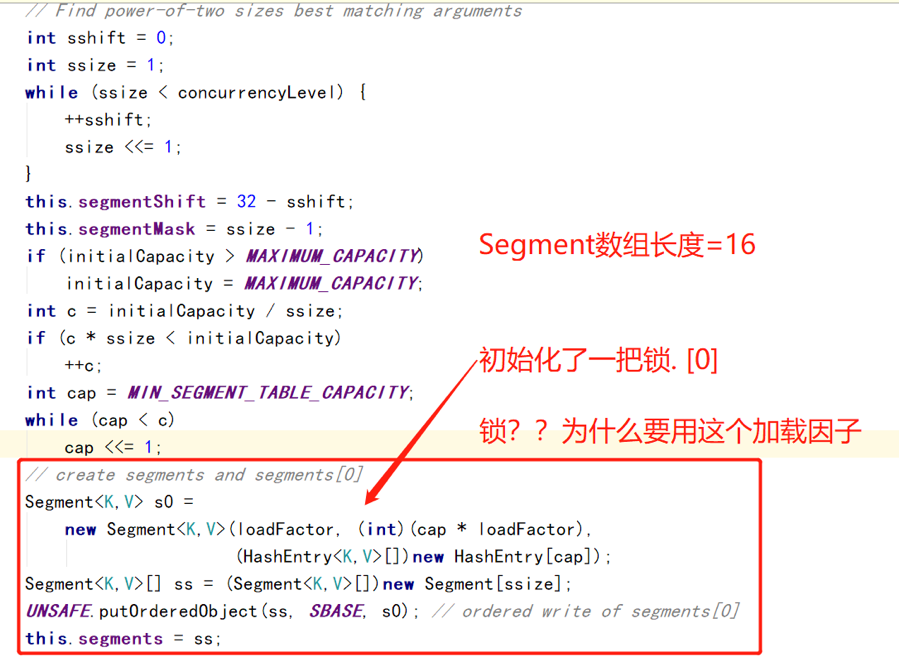
put
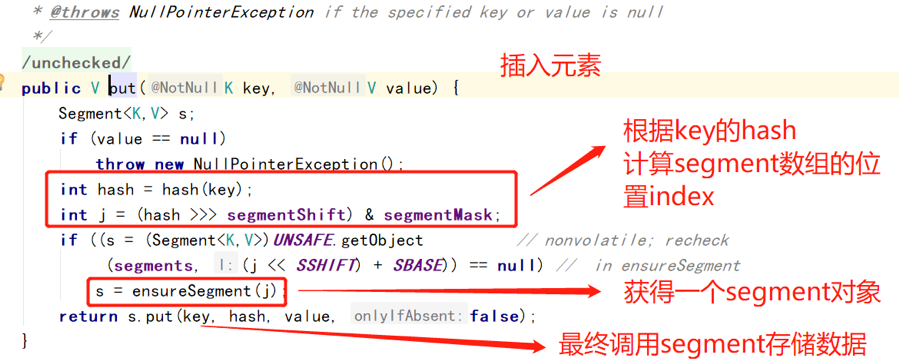
Segment.put
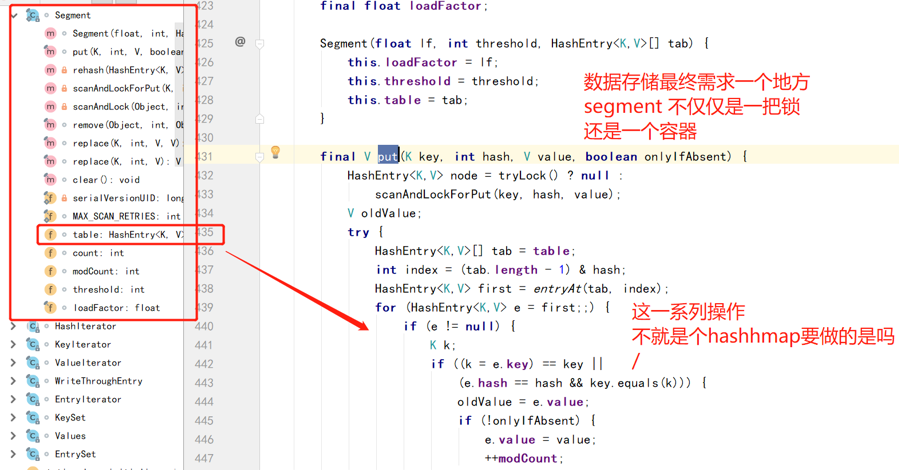
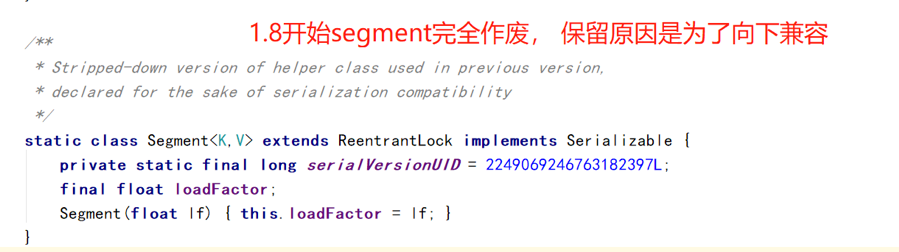
<=1.7segment(分段锁) = HashMap功能+Lock锁的功能 = 类似hashTable
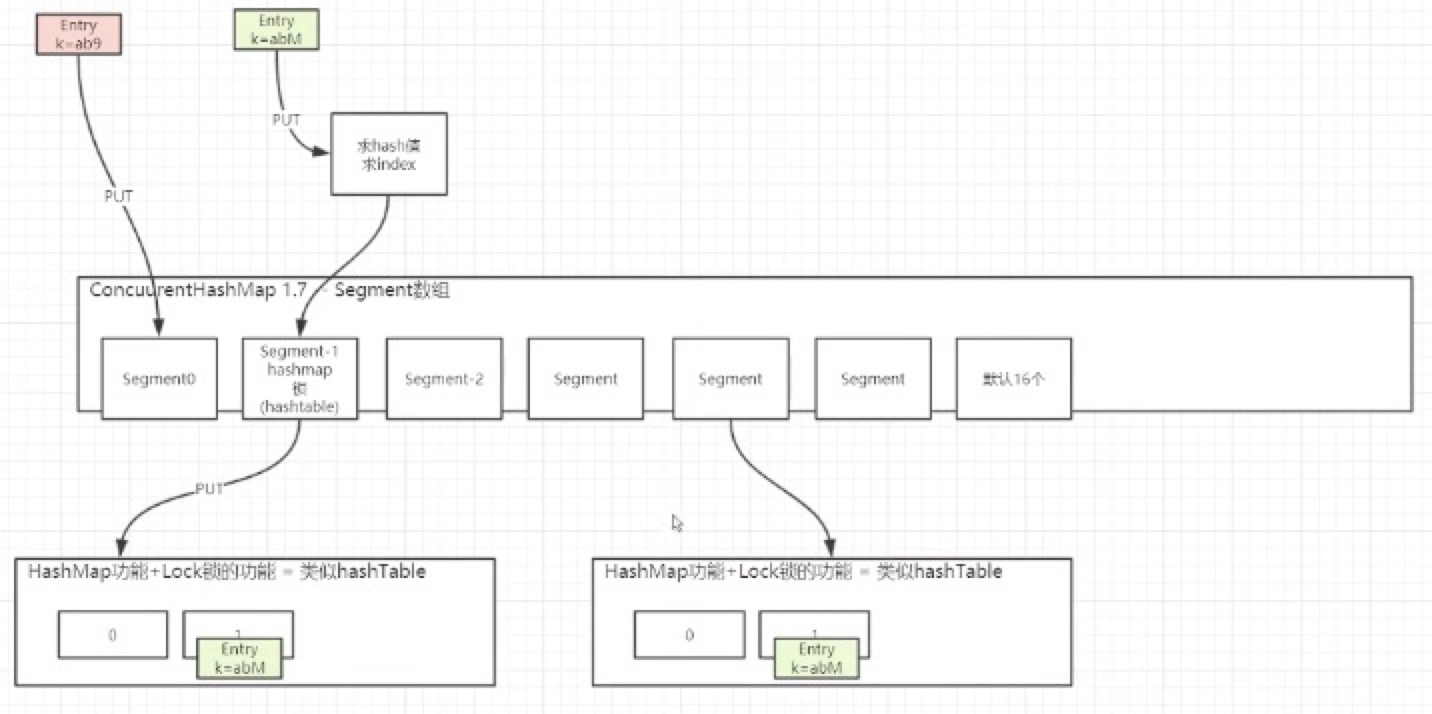
缺点:统计size,就是遍历每个segment,性能较差
1.8ConcurrentHashMap——— 没有segment概念
put
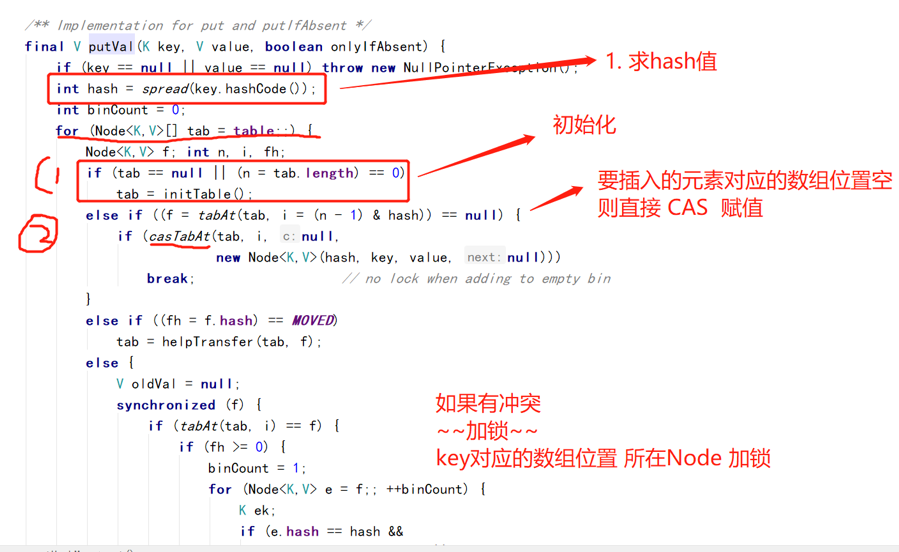无冲突的时候 CAS无锁
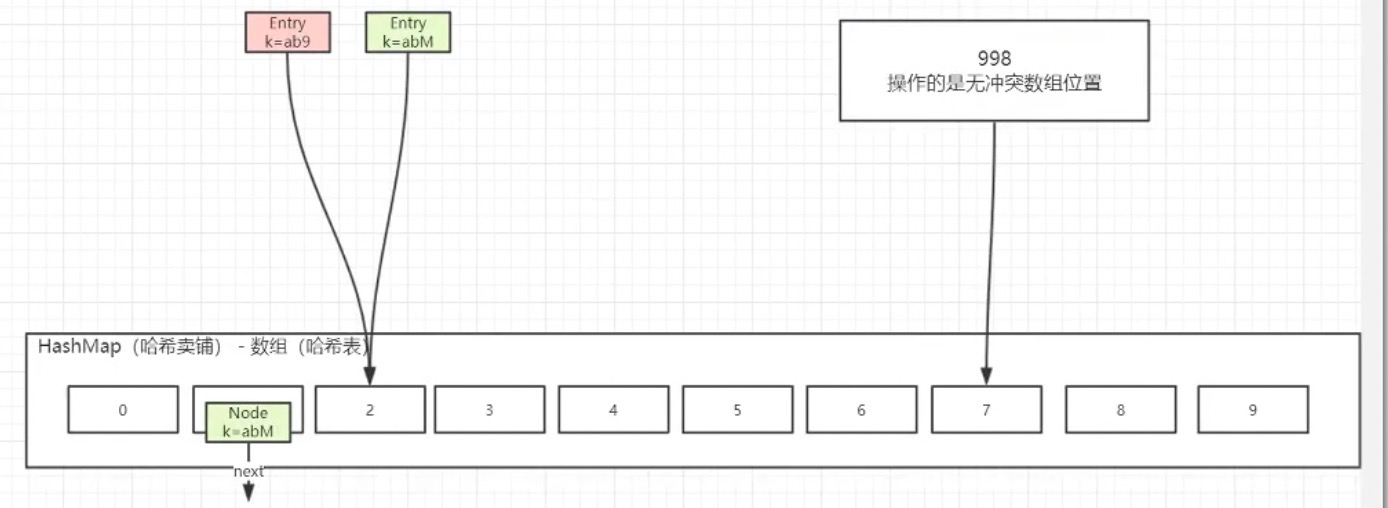
降低锁的粒度,减小冲突发生的可能性。