线程池-ForkJoin框架详解-FutureTask源码剖析
多线程应用
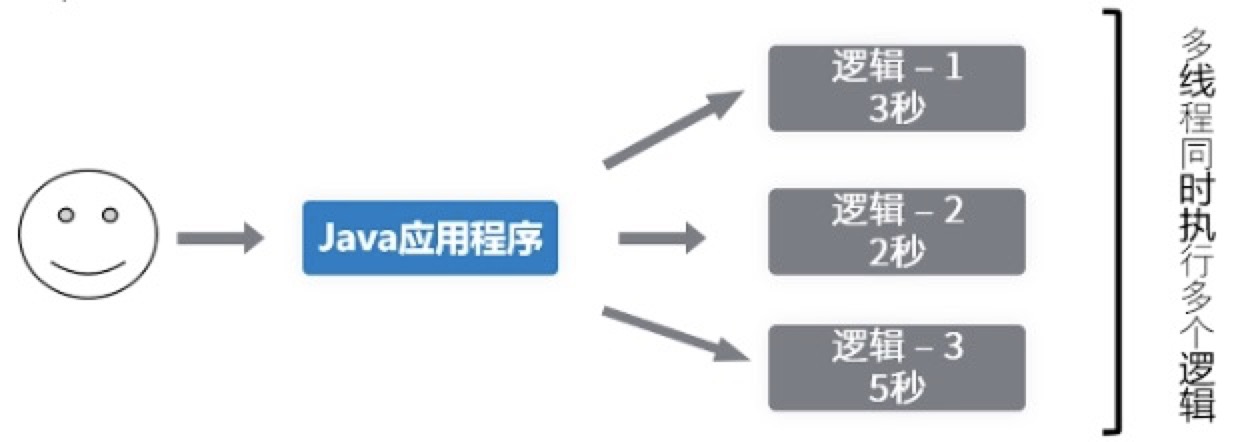
原本串行执行的程序,耗时3+2+5 = 10s的程序,时候缩短到<10。实际上是一种空间换时间的思想,对于用户来说响应时间是最重要的。
线程池
FutureTask
Callable VS Runnable
Callable的get方法有阻塞效果,如果任务结果还没有返回,那么就让线程等待,因此不需要像Runnable利用栅栏等待返回结果。
区别
1:方法名不同Callable为call(),Runnable为run()
2:call()有返回值,run()则无
3:call()会抛出异常,run()没有
源码解析
查看submit()源码
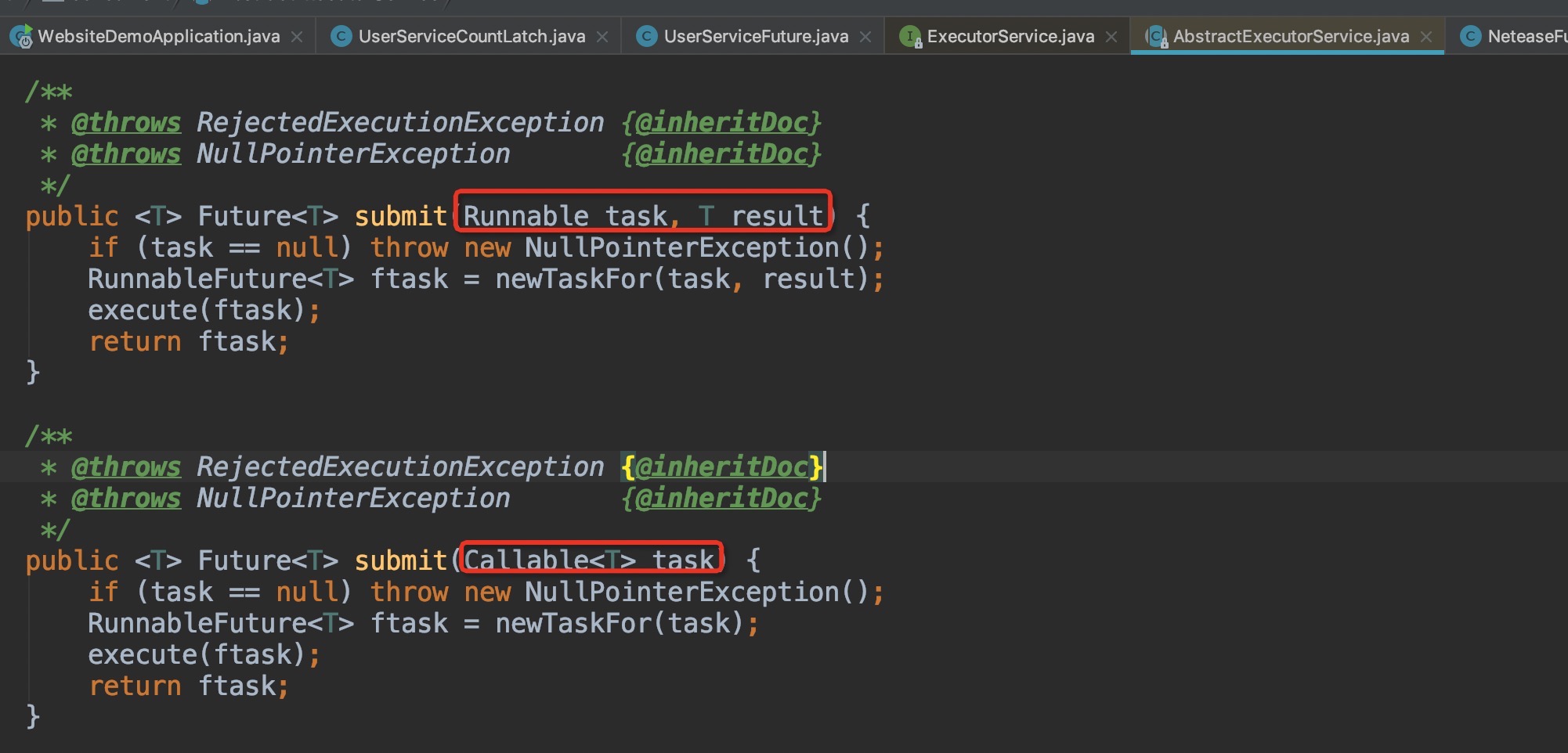
newTaskFor()
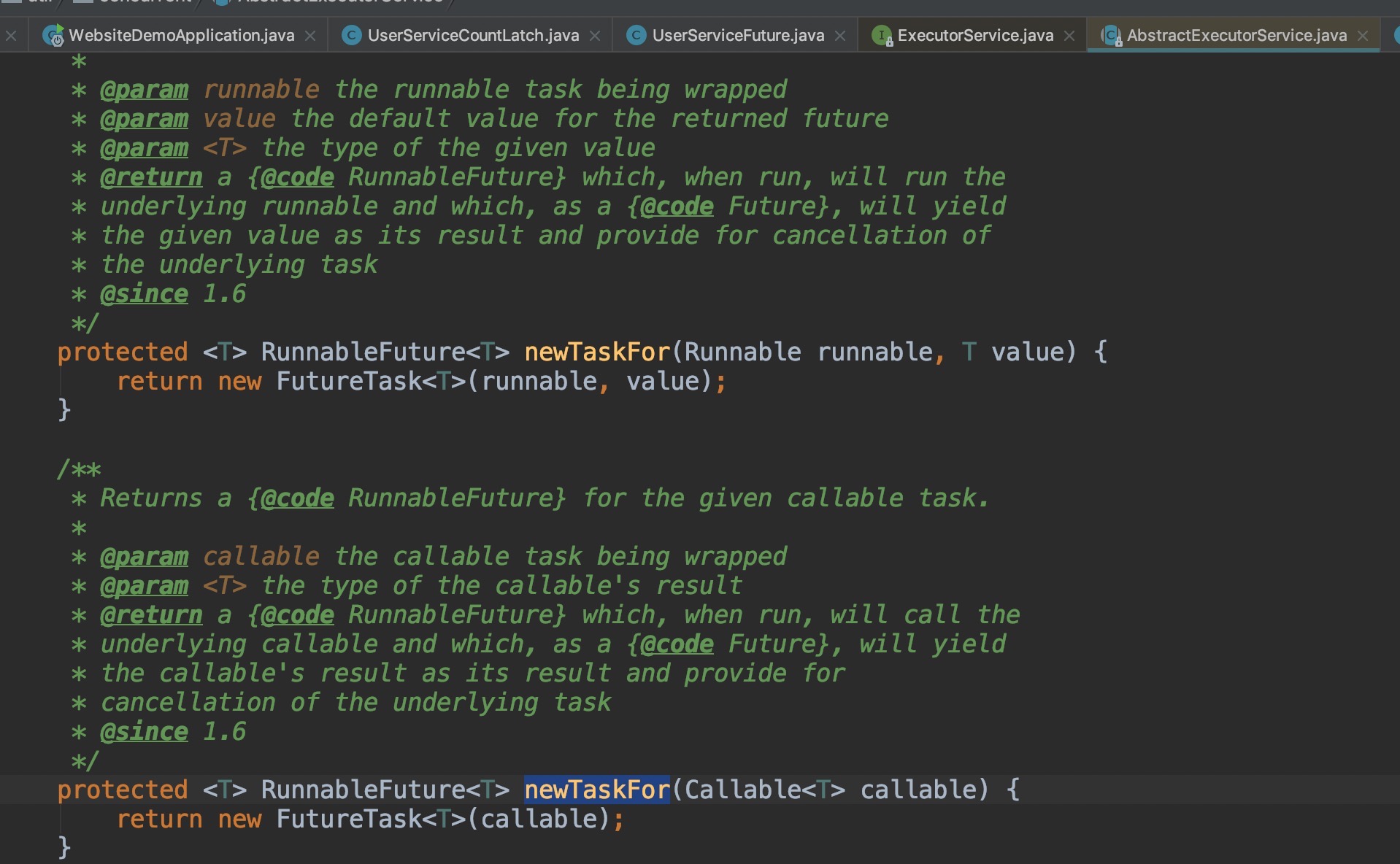
线程池里面任务 ——— 载体FutureTask, 线程去执行任务 ——— FutureTask
自己写一个FutureTask
1 | package com.study.thread.future.service; |
FutureTaskDemo此类仅供研究FutureTask的功能框架,实际生产中会存在线程不安全等问题,具体代码查看FutureTask源码
这是一个只实现基础功能的FutureTask,它继承了Runnable,再是利用park挂起获取result的线程,再result有结果返回时,unpark线程,实现Runnable的有返回值版本。
💡:为什么这个地方没有用CAS自旋锁的方式,而是park/unpark机制?
因为CAS自旋适合短时间内有返回的场景,比如入队列操作,而callable.call()方法是,调用方自己实现的,无法预估返回时间,用CAS自旋锁的形式会长时间占用CPU。
fork / join并发处理框架
用来做什么

demo
1 | package com.study.thread.future.service; |
意图梳理
任务拆分
关键点:分解任务fork出新任务(fork就是将拆分好的任务加入workQueue),汇集join任务执行结果(join就是返回执行结果),这就是任务拆分
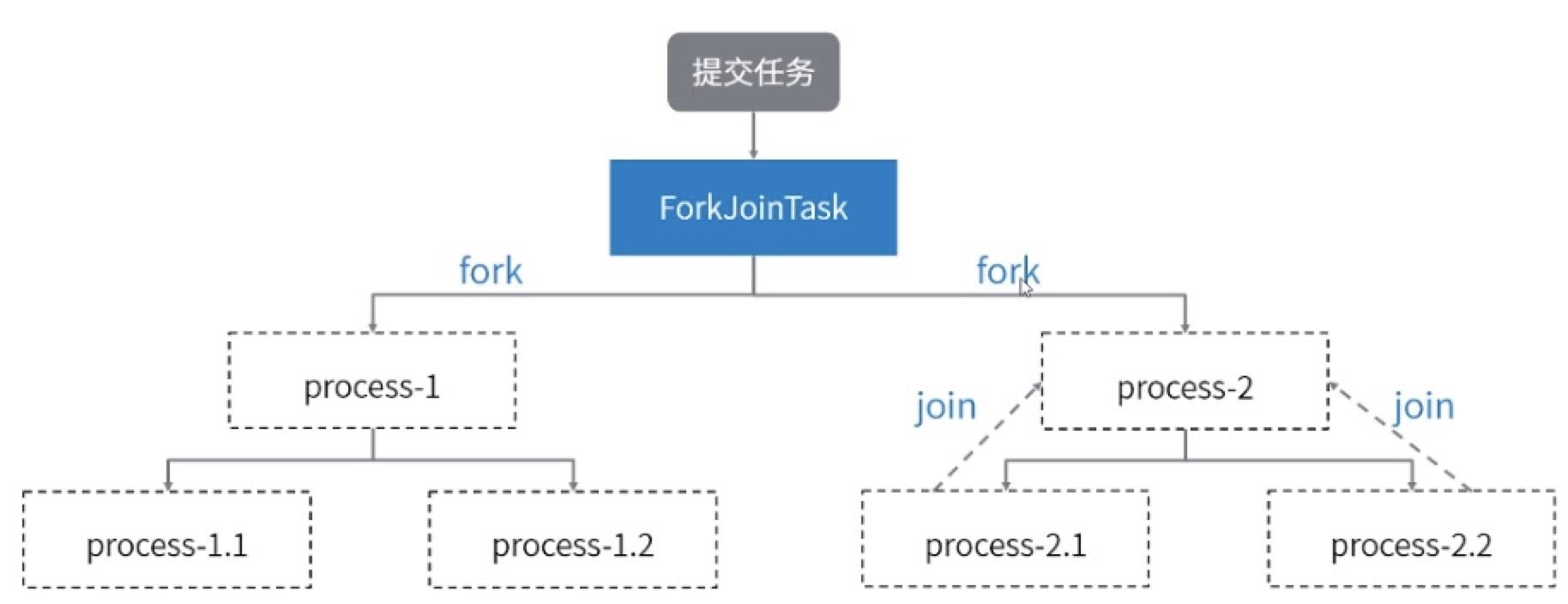
而在ExecutorService中,N个不同的任务需要submitN次
工作窃取
Fork-join和Future的另一个区别在于Fork-join里面不止一个workQueue,一个任务对应一个workQueue,每个workQueue对应一个Thread
Thread-2发下queue-2没有数据,Thread-2会去Thread-1中窃取任务,这就是工作窃取
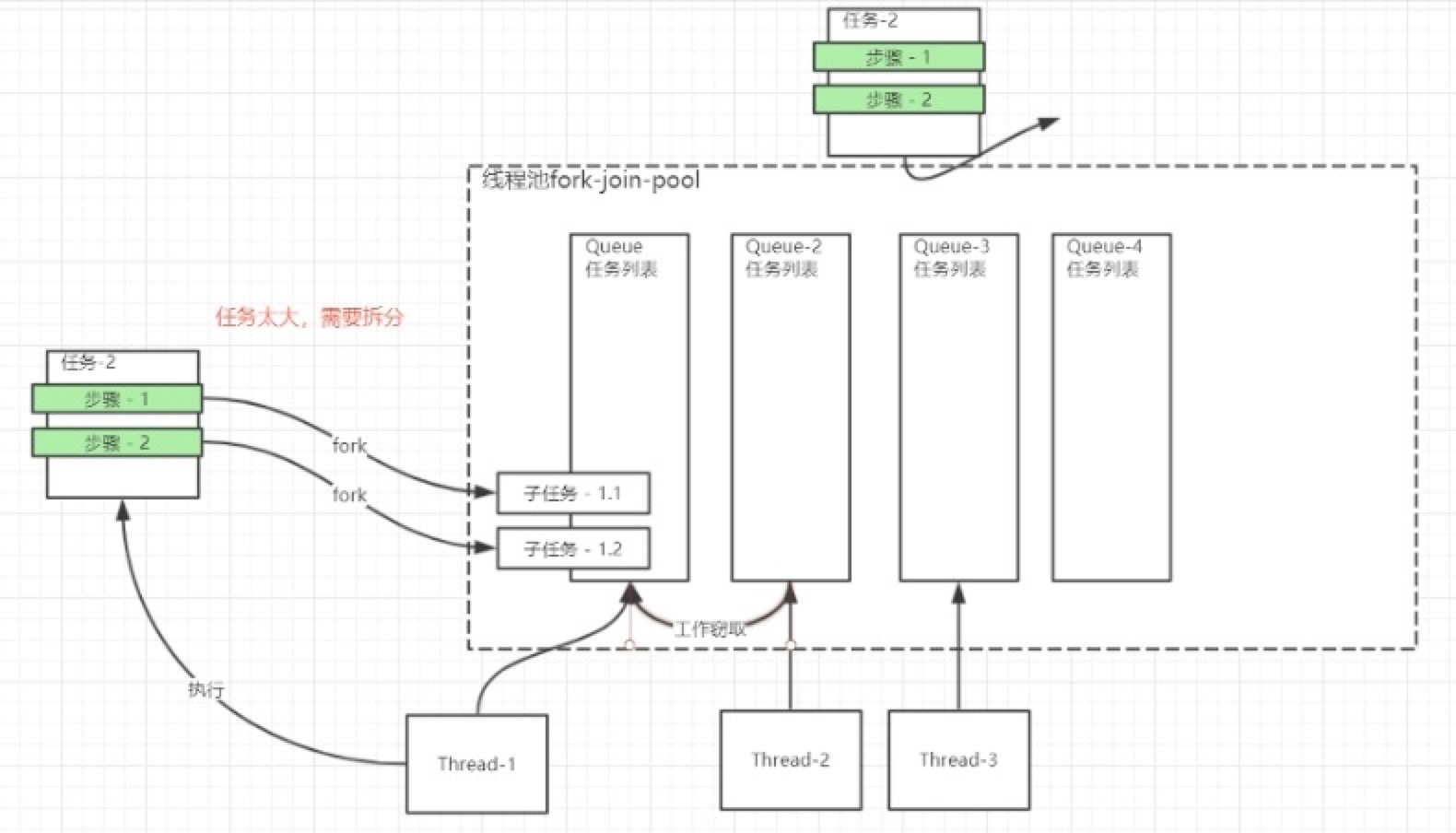
运用场景:大数据计算