CPU使用率
什么是CPU使用率?
CPU使用率是单位时间内CPU使用情况的统计,以百分比的方式展示。CPU 使用率,就是除了空闲时间外的其他时间占总 CPU 时间的百分比,
用公式来表示就是:
根据这个公式,可以从/proc/stat中的数据,就能计算出CPU使用率。
但是这个数据是开机以来的平均CPU使用率,一般没啥参考价值。
为了计算CPU使用率,性能工具一般都会取间隔一段时间(比如3s)的两次值,作差后,再计算出这段时间内的平均CPU使用率,即:

怎么查看CPU使用率
- top 显示了系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况。
- ps 则只显示了每个进程的资源使用情况。
top
- user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
- nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
- system(通常缩写为 sys),代表内核态 CPU 时间。
- idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
- iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
- irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。
- softirq(通常缩写为 si),代表处理软中断的 CPU 时间。
- steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
- guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
- guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
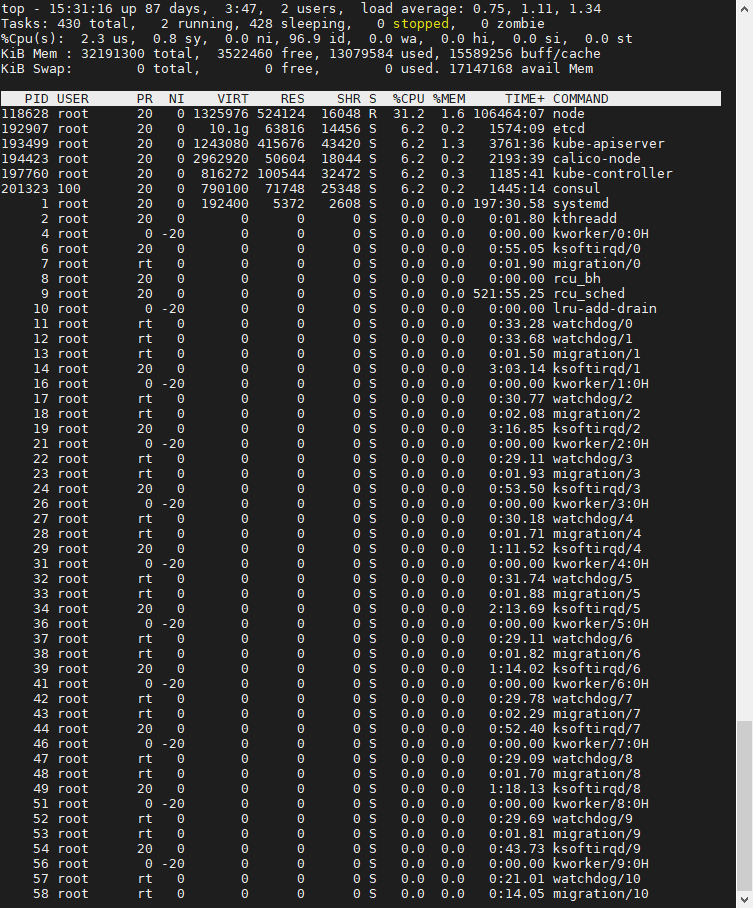
这个输出结果中,第三行 %Cpu 就是系统的 CPU 使用率,top 默认显示的是所有 CPU 的平均值,这个时候你只需要按下数字 1 ,就可以切换到每个 CPU 的使用率了。
空白行之后是进程的实时信息,每个进程都有一个 %CPU 列,表示进程的 CPU 使用率。它是用户态和内核态 CPU 使用率的总和,包括进程用户空间使用的 CPU、通过系统调用执行的内核空间 CPU 、以及在就绪队列等待运行的 CPU。在虚拟化环境中,它还包括了运行虚拟机占用的 CPU。
top 并没有细分进程的用户态 CPU 和内核态 CPU。
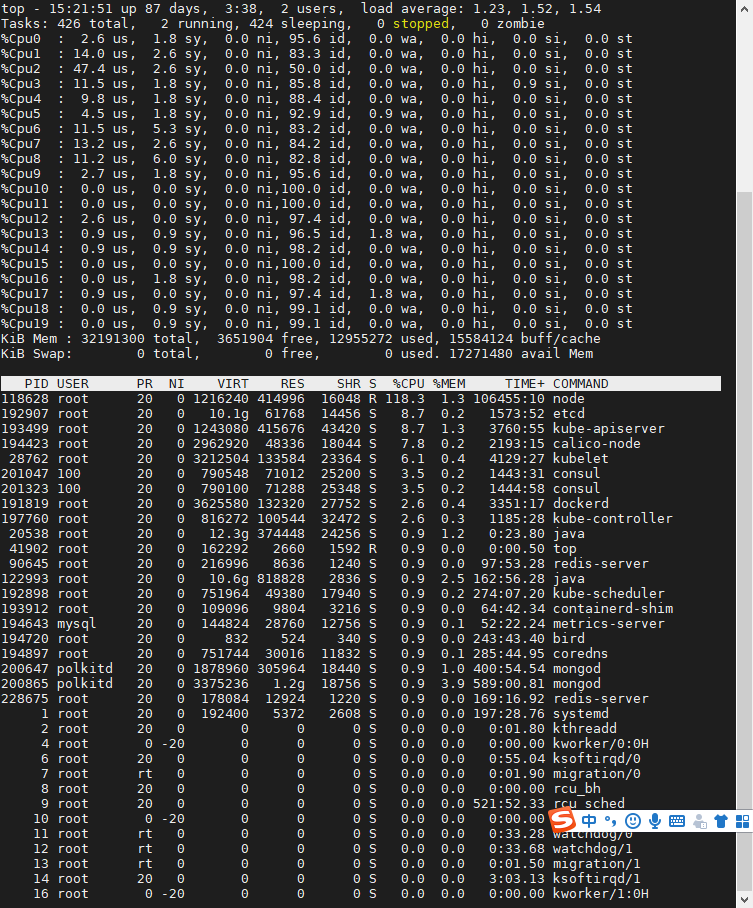
pidstat
- 用户态 CPU 使用率 (%usr);
- 内核态 CPU 使用率(%system);
- 运行虚拟机 CPU 使用率(%guest);
- 等待 CPU 使用率(%wait);
- 以及总的 CPU 使用率(%CPU)。
# 每隔 1 秒输出一组数据,共输出 5 组
CPU使用率过高怎么办?
——————使用 perf 分析 CPU 性能问题
案例
Nginx + PHP(php-fpm是 FastCGI 的实现,并提供了进程管理的功能。) 的 Web 服务为例,来看看当你发现 CPU 使用率过高的问题后,要怎么使用 top 等工具找出异常的进程,又要怎么利用 perf 找出引发性能问题的函数。
预先安装 docker、sysstat、perf、ab、bindfs 等工具
ab(apache bench)是一个常用的 HTTP 服务性能测试工具,这里用来模拟 Ngnix 的客户端。由于 Nginx 和 PHP 的配置比较麻烦,我把它们打包成了两个 Docker 镜像,这样只需要运行两个容器,就可以得到模拟环境。
注意,这个案例要用到两台虚拟机,如下图所示:
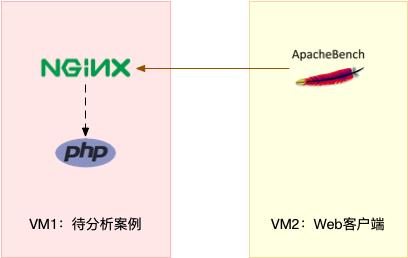
你可以看到,其中一台用作 Web 服务器,来模拟性能问题;另一台用作 Web 服务器的客户端,来给 Web 服务增加压力请求。使用两台虚拟机是为了相互隔离,避免“交叉感染”。
操作和分析
首先,在57终端执行下面的命令来运行 Nginx 和 PHP 应用:
1 | docker run --name nginx -p 10000:80 -itd feisky/nginx |
然后,在58终端使用 curl 访问 http://10.60.44.57:10000/,确认 Nginx 已正常启动。你应该可以看到 It works! 的响应。

接着,我们来测试一下这个 Nginx 服务的性能。在58终端运行下面的 ab 命令:
# 并发 10 个请求测试 Nginx 性能,总共测试 100 个请求——ab -c 10 -n 100 http://192.168.0.10:10000/
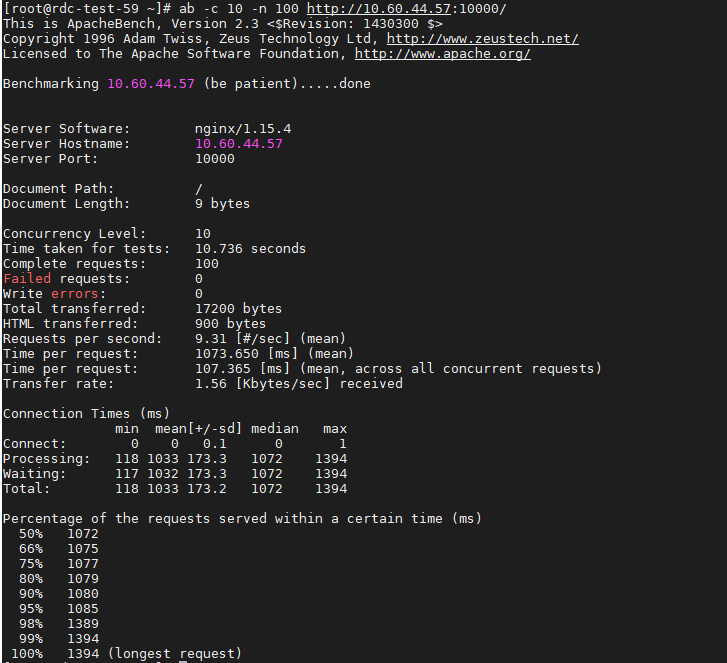
从 ab 的输出结果我们可以看到,Nginx 能承受的每秒平均请求数只有 9.31。用 top 和 pidstat 再来观察下。
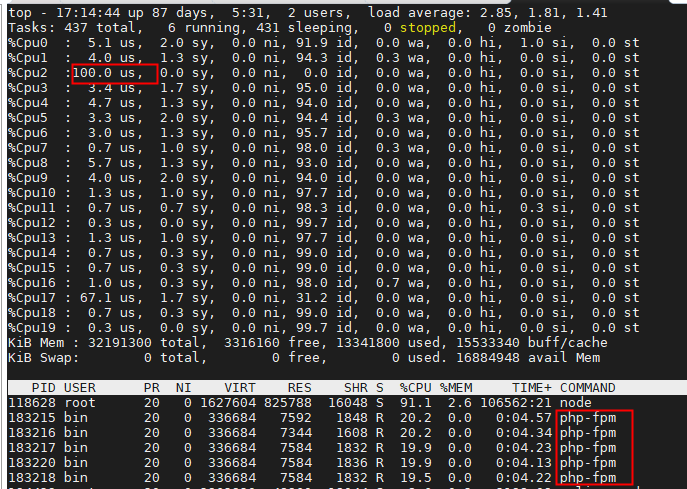
这里可以看到,系统中有几个 php-fpm 进程的 CPU 使用率达到 100%,达到饱和。这样,我们就可以确认,正是用户空间的 php-fpm 进程,导致 CPU 使用率骤升。
那再往下走,怎么知道是 php-fpm 的哪个函数导致了 CPU 使用率升高呢?我们来用 perf 分析一下。在第一个终端运行下面的 perf 命令:
1:制定符号路径为容器文件系统的路径
1 | mkdir /tmp/foo |
2:在容器外面把分析纪录保存下来,再去容器里查看结果
1 | perf record -g -p < pid> # 宿主机采样 |
按方向键切换到 php-fpm,再按下回车键展开 php-fpm 的调用关系,你会发现,调用关系最终到了 sqrt 和 add_function。看来,我们需要从这两个函数入手了。
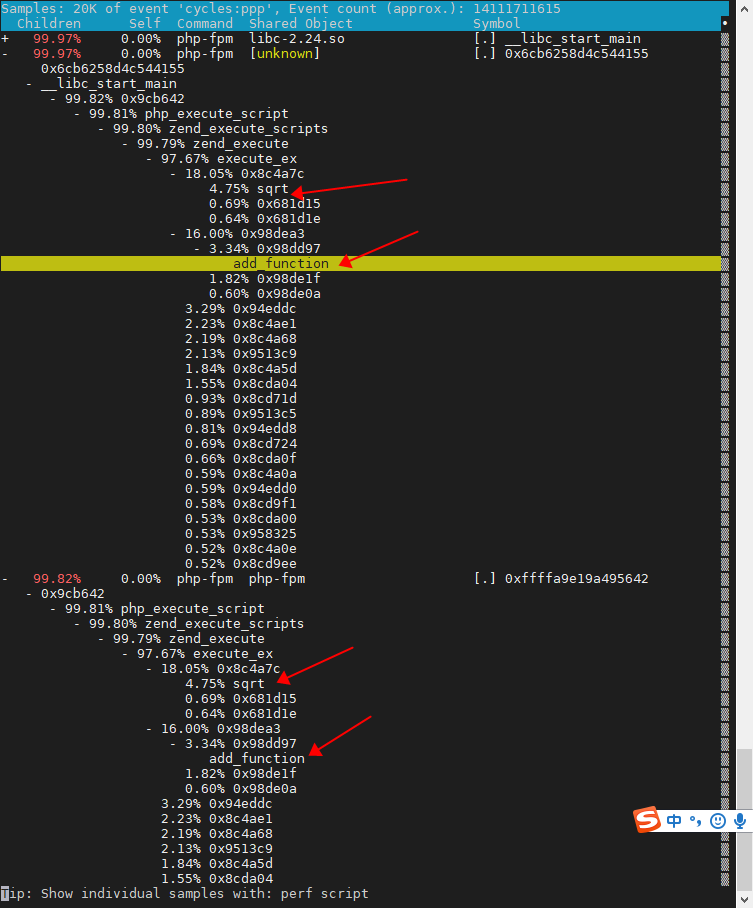
ps:为什么不用perf top -g -p
拷贝出 Nginx 应用的源码,看看是不是调用了这两个函数:
1 | 从容器 phpfpm 中将 PHP 源码拷贝出来 |
OK,原来只有 sqrt 函数在 app/index.php 文件中调用了。那最后一步,我们就该看看这个文件的源码了:
1 | cat app/index.php |
可以看到,这里有一个循环很多次的代码段
解决方法
找到问题的根源,就可以快速解决了,删除循环代码块
1 | <?php |
重启
1 | 停止原来的应用 |
接着,到58终端来验证一下修复后的效果。首先 Ctrl+C 停止之前的 ab 命令后,再运行下面的命令:
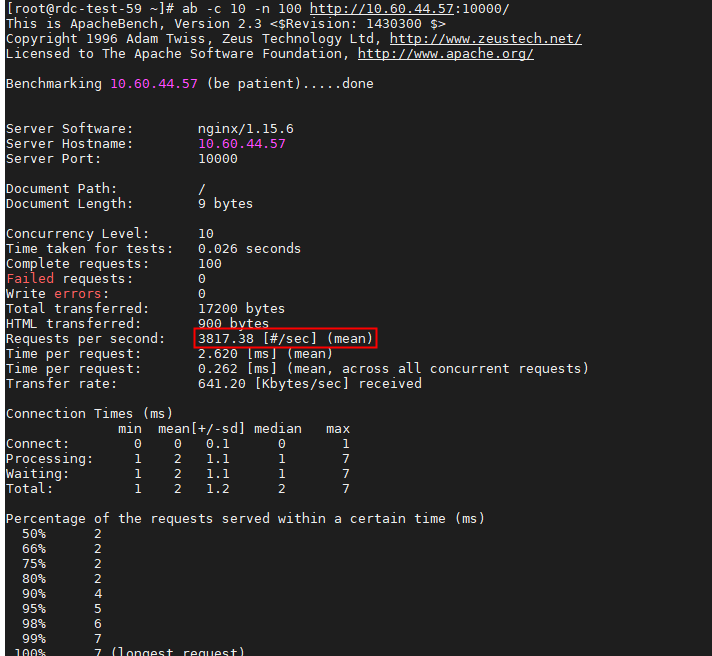
从这里你可以发现,现在每秒的平均请求数,已经从原来的 9.31 变成了 3817.38。
小结
CPU 使用率是最直观和最常用的系统性能指标,更是我们在排查性能问题时,通常会关注的第一个指标。所以我们更要熟悉它的含义,尤其要弄清楚用户(%user)、Nice(%nice)、系统(%system) 、等待 I/O(%iowait) 、中断(%irq)以及软中断(%softirq)这几种不同 CPU 的使用率。比如说:
- 用户 CPU 和 Nice CPU 高,说明用户态进程占用了较多的 CPU,所以应该着重排查进程的性能问题。
- 系统 CPU 高,说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调用的性能问题。
- I/O 等待 CPU 高,说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现了 I/O 问题。
- 软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的 CPU,所以应该着重排查内核中的中断服务程序。
碰到 CPU 使用率升高的问题,你可以借助 top、pidstat 等工具,确认引发 CPU 性能问题的来源;再使用 perf 等工具,排查出引起性能问题的具体函数。